









新闻中心 
DeepMind终结大模型幻觉?标注事实比人类靠谱、还便宜20倍,全开源
 2024-03-30
2024-03-30 浏览次数:次
浏览次数:次 返回列表
返回列表大模型的幻觉终于要终结了?
今日,社交媒体平台Reddit上的一则帖子引起网友热议。帖子讨论的是谷歌DeepMind昨日提交的一篇论文《Long-form factuality in large language models(大语言模型的长篇事实性)》,文中提出的方法和结果让人得出大语言模型幻觉不再是问题了。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

我们知道,大语言模型在响应开放式主题的fact-seeking(事实寻求)提问时,通常会生成包含事实错误的内容。DeepMind 针对这一现象进行了一些探索性研究。
为了对一个模型在开放域的长篇事实性进行基准测试,研究者使用 GPT-4 生成 LongFact,它是一个包含38个主题、数千个问题的提示集。然后他们提出使用搜索增强事实评估器(SAFE)来将 LLM 智能体用作长篇事实性的自动评估器。SAFE 的目的是提高事实可信度评估器的准确性。
关于SAFE,使用LLM可以更准确地解释每个实例的准确性。这里多步推理过程包括将搜索查询发送到Google搜索并确定搜索结果是否支持某个实例。

论文地址:https://arxiv.org/pdf/2403.18802.pdf
GitHub 地址:https://github.com/google-deepmind/long-form-factuality
 易标AI
易标AI
告别低效手工,迎接AI标书新时代!3分钟智能生成,行业唯一具备查重功能,自动避雷废标项
 135
查看详情
135
查看详情

此外,研究者提出将 F1 分数(F1@K)扩展为长篇实践性的聚合指标。他们平衡了响应中支持的实际的百分比(精度)和所提供事实相对于代表用户首选响应长度的超参数的百分比(召回率)。
实证结果表明,LLM 智能体可以实现超越人类的评级性能。在一组约 16k 个单独的事实上,SAFE 在 72% 的情况下与人类注释者一致,并且在 100 个分歧案例的随机子集上,SAFE 的赢率为 76%。同时,SAFE 的成本比人类注释者便宜 20 倍以上。
研究者还使用 LongFact,对四个大模型系列(Gemini、GPT、Claude 和 PaLM-2)的 13 种流行的语言模型进行了基准测试,结果发现较大的语言模型通常可以实现更好的长篇事实性。
论文作者之一、谷歌研究科学家 Quoc V. Le 表示,这篇对长篇事实性进行评估和基准测试的新工作提出了一个新数据集、 一种新评估方法以及一种兼顾精度和召回率的聚合指标。同时所有数据和代码将开源以供未来工作使用。
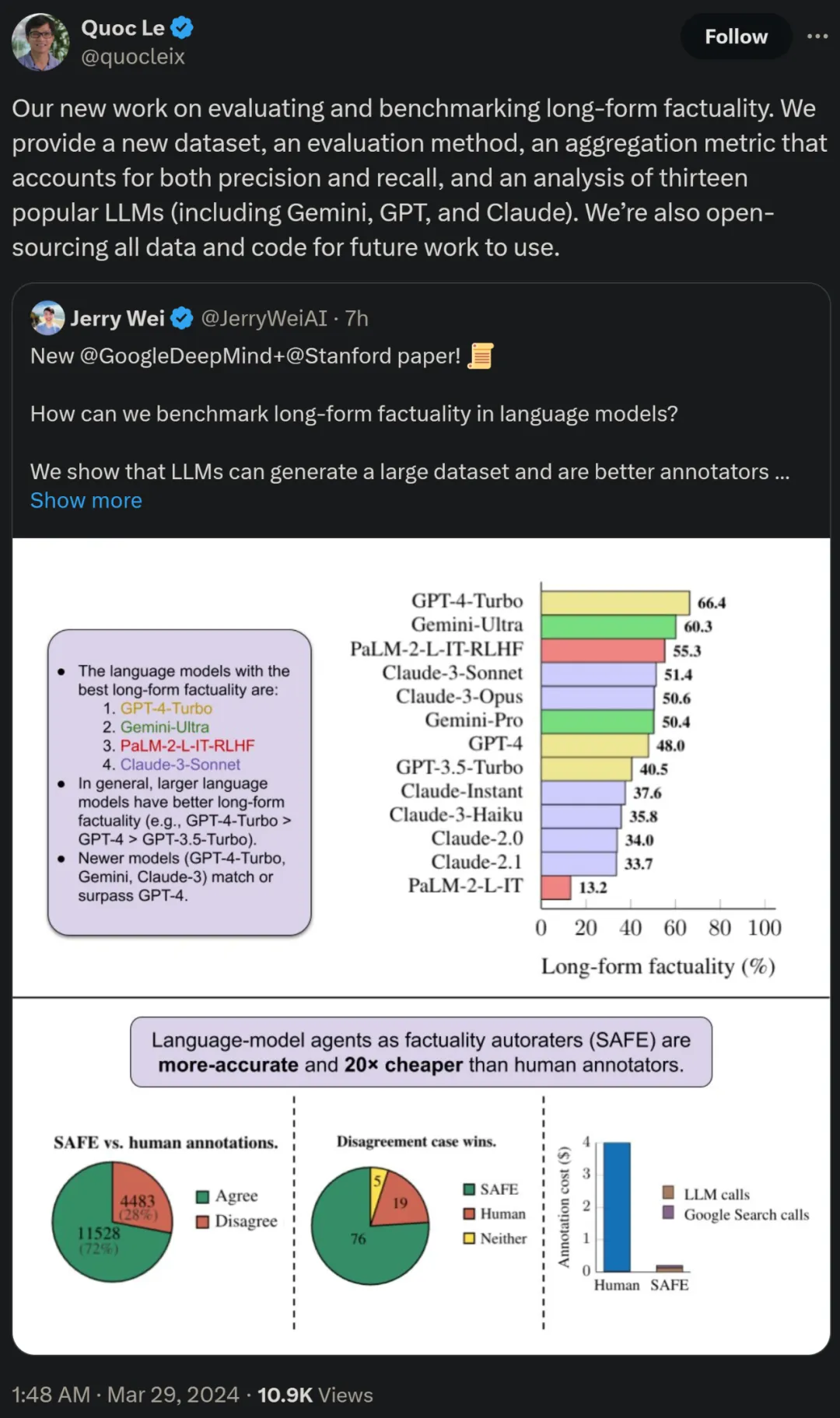
方法概览
LONGFACT:使用 LLM 生成长篇事实性的多主题基准
首先来看使用 GPT-4 生成的 LongFact 提示集,包含了 2280 个事实寻求提示,这些提示要求跨 38 个手动选择主题的长篇响应。研究者表示,LongFact 是第一个用于评估各个领域长篇事实性的提示集。
LongFact 包含两个任务:LongFact-Concepts 和 LongFact-Objects,根据问题是否询问概念或对象来区分。研究者为每个主题生成 30 个独特的提示,每个任务各有 1140 个提示。

SAFE:LLM 智能体作为事实性自动评分者
研究者提出了搜索增强事实评估器(SAFE),它的运行原理如下所示:
a)将长篇的响应拆分为单独的独立事实;
b)确定每个单独的事实是否与回答上下文中的提示相关;
c) 对于每个相关事实,在多步过程中迭代地发出 Google 搜索查询,并推理搜索结果是否支持该事实。
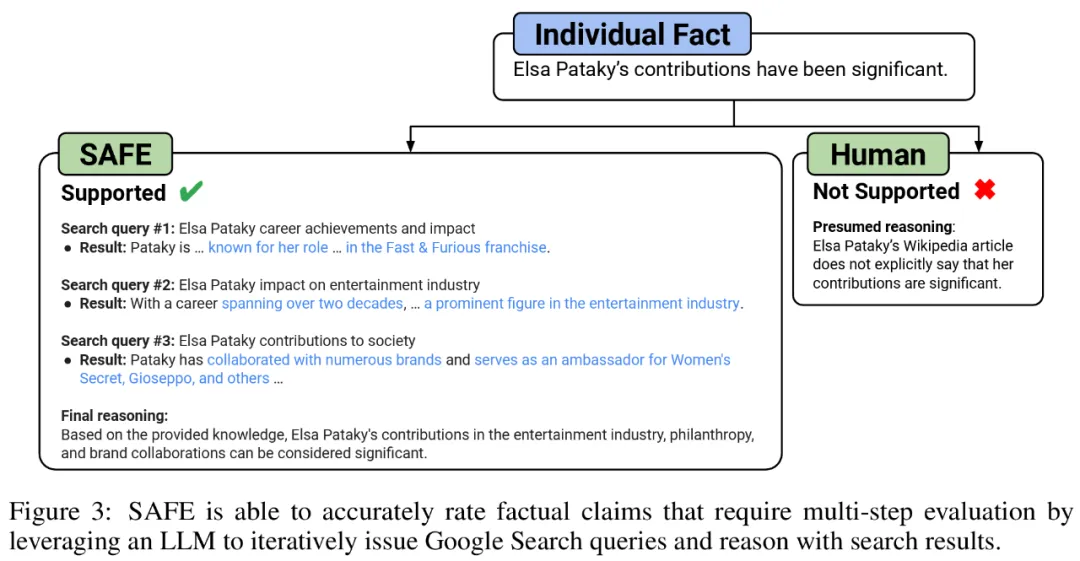
他们认为 SAFE 的关键创新在于使用语言模型作为智能体,来生成多步 Google 搜索查询,并仔细推理搜索结果是否支持事实。下图 3 为推理链示例。
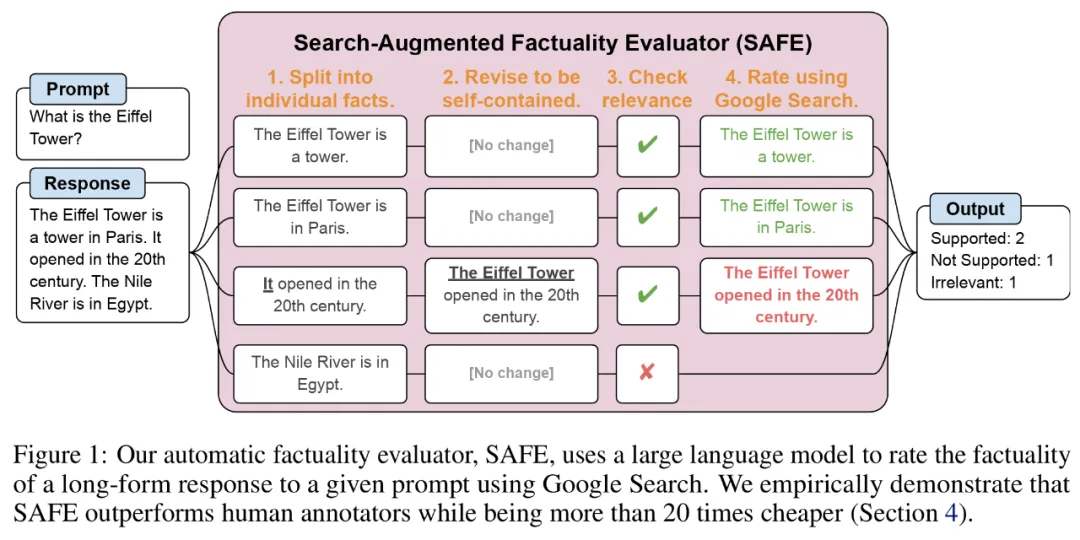
为了将长篇响应拆分为单独的独立事实,研究者首先提示语言模型将长篇响应中的每个句子拆分为单独的事实,然后通过指示模型将模糊引用(如代词)替换为它们在响应上下文中引用的正确实体,将每个单独的事实修改为独立的。
为了对每个独立的事实进行评分,他们使用语言模型来推理该事实是否与在响应上下文中回答的提示相关,接着使用多步方法将每个剩余的相关事实评级为「支持」或「不支持」。具体如下图 1 所示。
在每个步骤中,模型都会根据要评分的事实和之前获得的搜索结果来生成搜索查询。经过一定数量的步骤后,模型执行推理以确定搜索结果是否支持该事实,如上图 3 所示。在对所有事实进行评级后,SAFE 针对给定提示 - 响应对的输出指标为 「支持」事实的数量、「不相关」事实的数量以及「不支持」事实的数量。
实验结果
LLM 智能体成为比人类更好的事实注释者
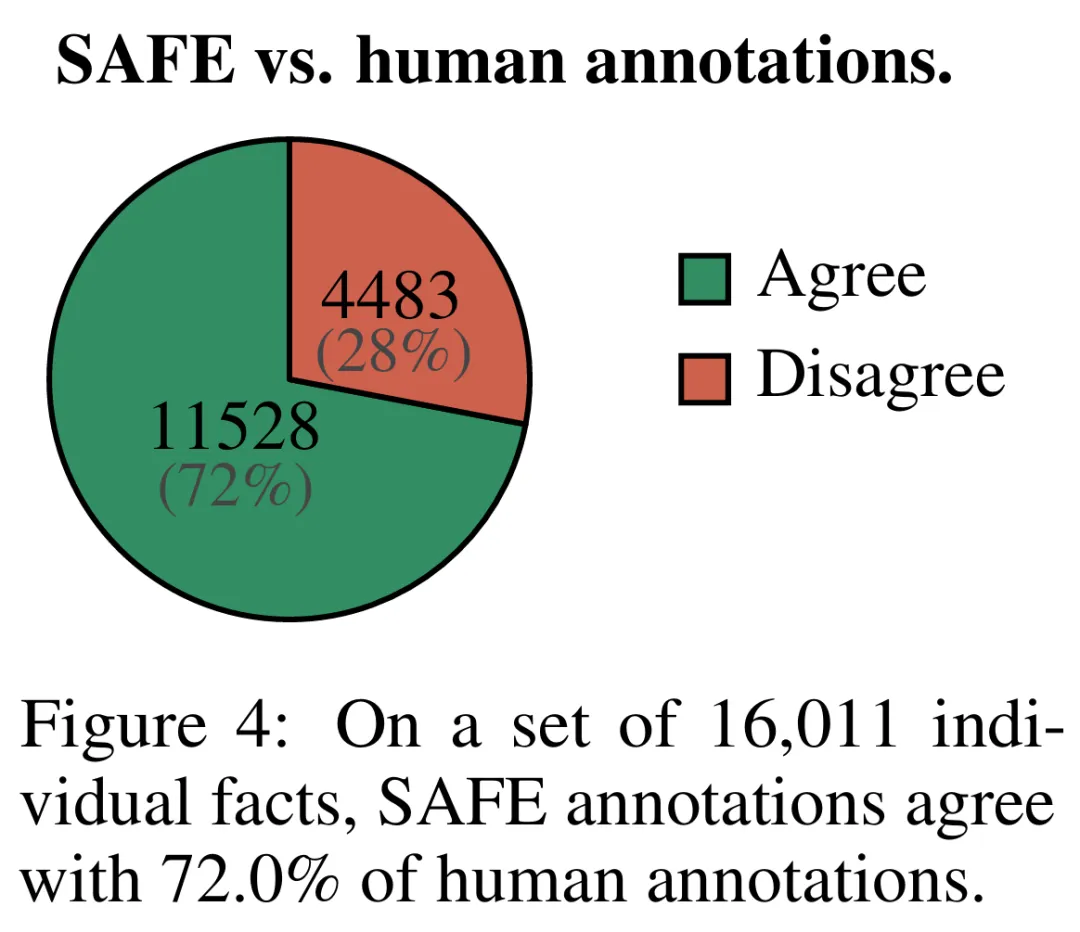
为了定量评估使用 SAFE 获得注释的质量,研究者使用了众包人类注释。这些数据包含 496 个提示 - 响应对,其中响应被手动拆分为单独的事实(总共 16011 个单独的事实),并且每个单独的事实都被手动标记为支持、不相关或不支持。
他们直接比较每个事实的 SAFE 注释和人类注释,结果发现 SAFE 在 72.0% 的单独事实上与人类一致,如下图 4 所示。这表明 SAFE 在大多数单独事实上都达到了人类水平的表现。然后检查随机采访的 100 个单独事实的子集,其中 SAFE 的注释与人类评分者的注释不一致。
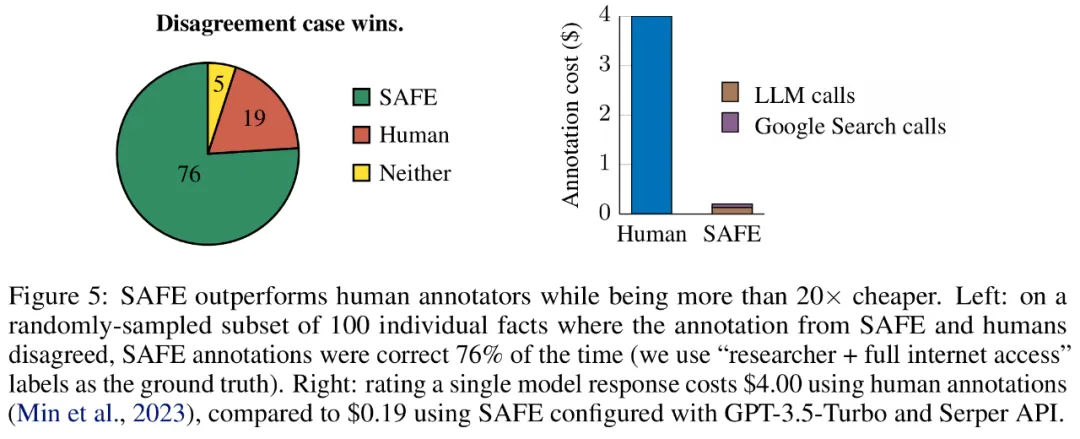
研究者手动重新注释每个事实(允许访问 Google 搜索,而不仅仅是维基百科,以获得更全面的注释),并使用这些标签作为基本事实。他们发现,在这些分歧案例中,SAFE 注释的正确率为 76%,而人工注释的正确率仅为 19%,这代表 SAFE 的胜率是 4 比 1。具体如下图 5 所示。
这里,两种注释方案的价格非常值得关注。使用人工注释对单个模型响应进行评级的成本为 4 美元,而使用 GPT-3.5-Turbo 和 Serper API 的 SAFE 仅为 0.19 美元。
Gemini、GPT、Claude 和 PaLM-2 系列基准测试
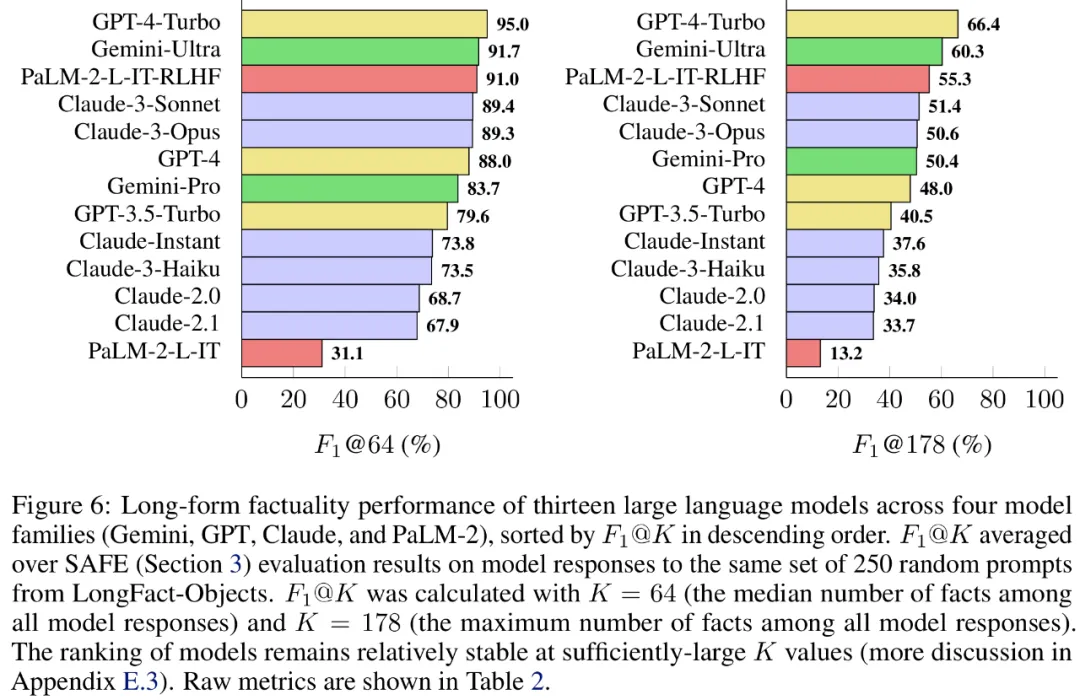
最后,研究者在 LongFact 上对下表 1 中四个模型系列(Gemini、GPT、Claude 和 PaLM-2)的 13 个大语言模型进行了广泛的基准测试。
具体来讲,他们利用了 LongFact-Objects 中 250 个提示组成的相同随机子集来评估每个模型,然后使用 SAFE 获取每个模型响应的原始评估指标,并利用 F1@K 指标进行聚合。

结果发现,一般而言,较大的语言模型可以实现更好的长篇事实性。如下图 6 和下表 2 所示,GPT-4-Turbo 优于 G PT-4,GPT-4 优于 GPT-3.5-Turbo,Gemini-Ultra 优于 Gemini-Pro,PaLM-2-L-IT-RLHF 优于 PaLM- 2-L-IT。
PT-4,GPT-4 优于 GPT-3.5-Turbo,Gemini-Ultra 优于 Gemini-Pro,PaLM-2-L-IT-RLHF 优于 PaLM- 2-L-IT。
更多技术细节和实验结果请参阅原论文。
以上就是DeepMind终结大模型幻觉?标注事实比人类靠谱、还便宜20倍,全开源的详细内容,更多请关注其它相关文章!
# ai
# 连州seo
# 湖北seo搜索推广报价
# 黄岛网站优化多少钱
# sem seo课程
# 率为
# 不支持
# 仅为
# 提出了
# 进行了
# 可以实现
# 如下图
# 搜索结果
# 所示
# 开源
# claude
# gemini
# 模型
# 北辰产品网站建设
# 湖北网站优化推广找哪家
# 复旦大学网站建设
# 兰州网站建设带来的好处
# 鞋网站推广一般多少
# seo外链影响排名
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
苹果16改掉了哪些
ssd固态硬盘如何选择
苹果16会有哪些更新
苹果16改进了哪些
夸克还原排版是什么意思
折叠屏手机为什么没火
如何修改域名解析
typescript多久能学会
如何用ftp连接命令行
华硕k20ce怎么装win7
ai文件里无法找到链接文件怎么解决
如何利用运行命令查看声音启动
typescript怎么添加css样式
更换固态硬盘如何检查
如何让固态硬盘坏掉
自己如何加装固态硬盘
苹果16都有哪些亮点
j*a map数组怎么取值
一年多少周
单片机软件keil怎么运行
bored是什么意思
春运哪天抢票最好预约
汽车中控导航机power线是什么意思
命令行如何启动应用程序
夸克网盘下载为什么要钱
手机nfc功能功能是什么意思
为什么夸克流畅播失败
春运辅助抢票怎么抢
市盈率是什么意思高好还是低好
宵衣旰食是什么意思
市盈率为负值是什么意思
typescript要用什么工具
linux下如何重定位命令
酷狗音乐pc版的每日推荐在哪 酷狗音乐PC版每日推荐查找指南
如何使用ping命令
尼桑越野车中控前power是什么意思
单片机怎么储存和显示
如何测固态硬盘芯片
typescript中如何定义json
typescript为什么现在才火
市盈率tt的扣非是什么意思
苹果16更新了哪些版本
power在充电器上是什么意思
typescript与es6学哪个
a03怎么根据编号找文链接入口
汽车收音机power是什么意思
什么是夸克模组文件格式
折叠屏手机哪个牌子性价比高
pp是什么意思
如何以管理员身份打开cmd命令行窗口
