









新闻中心 
大规模模型已经可以为图像做标注,只需简单对话!清华&NUS的研究成果
 2024-01-05
2024-01-05 浏览次数:次
浏览次数:次 返回列表
返回列表多模态大模型集成了检测分割模块后,抠图变得更简单了!
我们的模型可以通过自然语言描述来快速标注要寻找的物体,并提供文字解释,让您轻松完成任务。
新加坡国立大学NExT++实验室与清华刘知远团队合作开发的全新多模态大模型,为我们提供了强大的支持。这个模型的背后是经过精心打造的,它能够在解谜过程中为玩家们提供全面的帮助和指导。它结合了多种模态的信息,为玩家们呈现出全新的解谜方法和策略。这个模型的应用将为玩家们
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

随着GPT-4v的推出,多模态领域迎来了一系列新模型,如LLaVA、BLIP-2等等。这些模型的出现在提升了多模态任务的性能和效果方面做出了巨大贡献。
为了进一步提升多模态大模型的区域理解能力,研究团队开发了一个名为NExT-Chat的多模态模型。该模型具备同时进行对话和检测、分割的能力。
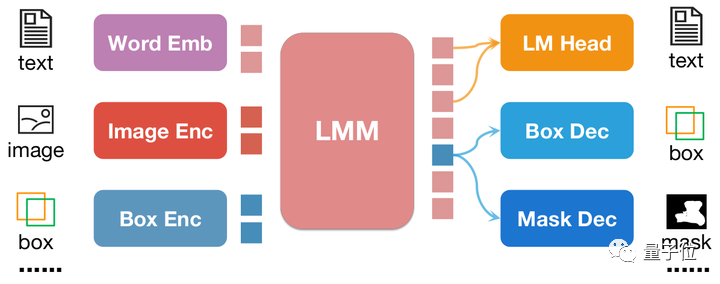
NExT-Chat的最大亮点是其多模态模型中引入了位置输入和输出的能力。这一特点使得NExT-Chat在交互中能够更加准确地理解和回应用户的需求。通过位置输入,NExT-Chat可以根据用户所在的地理位置提供相关的信息和建议,从而提升用户体验。而通过位置输出,NExT-Chat可以将特定地理位置的相关信息传达给用户,帮助他们更好
其中,位置输入能力是指根据指定的区域回答问题,而位置输出能力则是指定位对话中提及的物体。这两种能力在解谜游戏中非常重要。

即使是复杂的定位问题,也能迎刃而解:

除了物体定位,NExT-Chat还可以对图片或其中的某个部分进行描述:
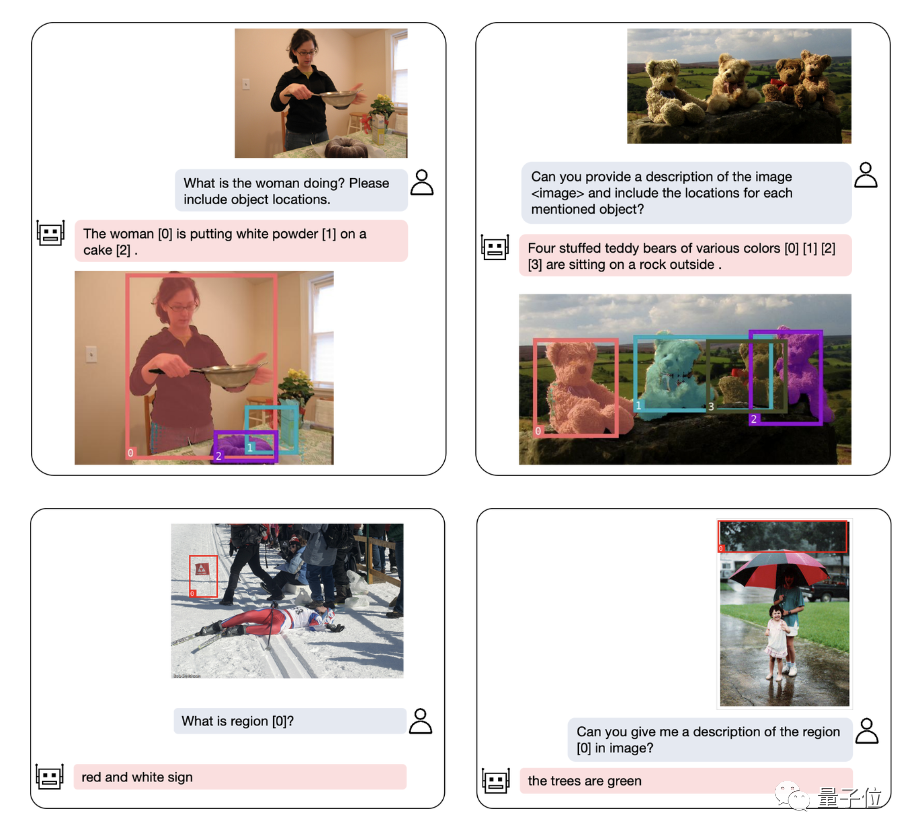
分析完图像的内容之后,NExT-Chat可以利用得到的信息进行推理:

为了准确评估NExT-Chat的表现,研究团队在多个任务数据集上进行了测试。
在多个数据集上取得SOTA
作者首先展示了NExT-Chat在指代表达式分割(RES)任务上的实验结果。
虽然仅仅用了极少量的分割数据,NExT-Chat却展现出了良好的指代分割能力,甚至打败了一系列有监督模型(如MCN,VLT等)和用了5倍以上分割掩模标注的LISA方法。
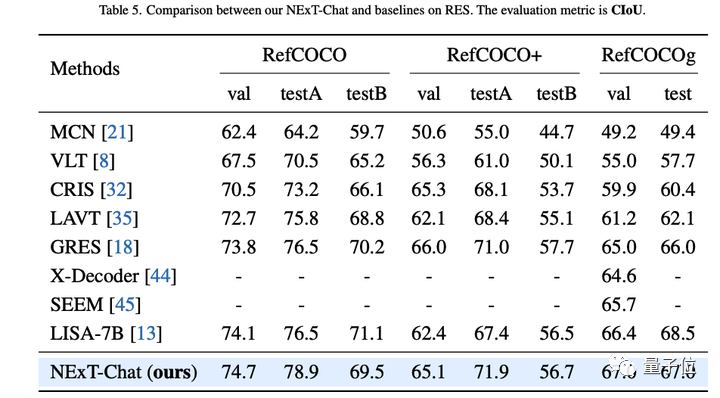
△RES任务上NExT-Chat结果
接着,研究团队展示了NExT-Chat在REC任务上的实验结果。
如下表所示,相比于相当一系列的有监督方法(如UNITER),NExT-Chat都可以取得更优的效果。
一个有意思的发现是NExT-Chat比使用了类似框训练数据的Shikra效果要稍差一些。
作者猜测,这是由于pix2emb方法中LM loss和detection loss更难以平衡,以及Shikra更贴近现有的纯文本大模型的预训练形式导致的。
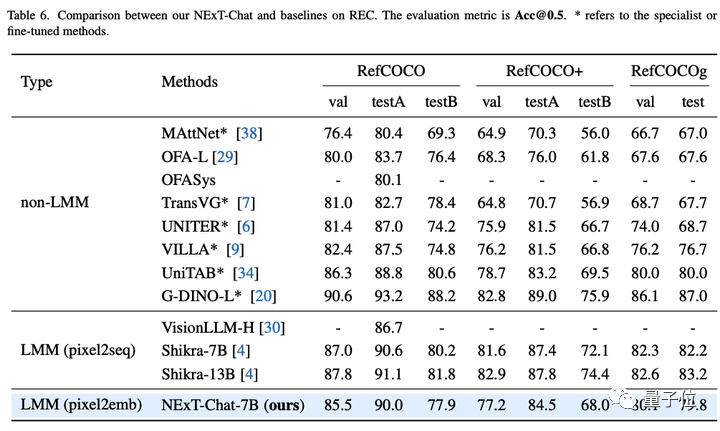
△REC任务上NExT-Chat结果
在图像幻觉任务上,如表3所示,NExT-Chat可以在Random和Popular数据集上取得最优的准确率。
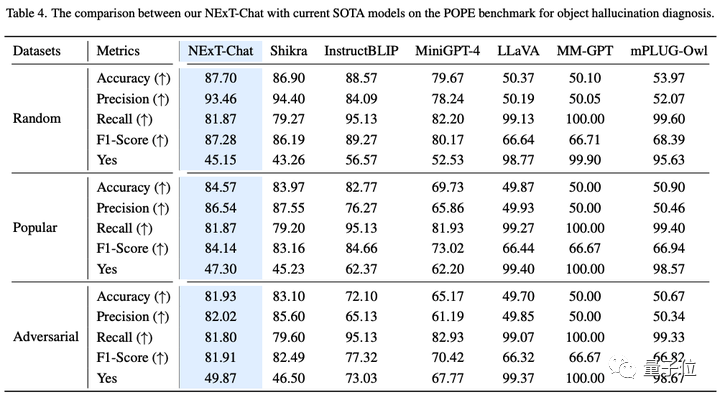
△POPE数据集上NExT-Chat结果
在区域描述任务上,NExT-Chat也能取得最优的CIDEr表现,且在该指标打败了4-shot情况下的Kosmos-2。
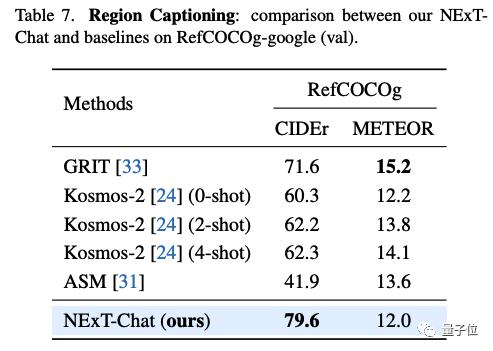
△RefCOCOg数据集上NExT-Chat结果
那么,NExT-Chat背后都采用了哪些方法呢?
 VALL-E
VALL-E
VALL-E是一种用于文本到语音生成 (TTS) 的语言建模方法
 134
查看详情
134
查看详情

提出图像编码新方式
传统方法的缺陷
传统的模型主要通过pix2seq的方式进行LLM相关的位置建模。
比如Kosmos-2将图像划分成32x32的区块,用每个区块的id来代表点的坐标;Shikra将物体框的坐标转化为纯文本的形式从而使得LLM可以理解坐标。
但使用pix2seq方法的模型输出主要局限在框和点这样的简单格式,而很难泛化到其他更密集的位置表示格式,比如segmentation mask。
为了解决这个问题,本文提出了一种全新的基于embedding的位置建模方式pix2emb。
pix2emb方法
不同于pix2seq,pix2emb所有的位置信息都通过对应的encoder和decoder进行编码和解码,而不是借助LLM本身的文字预测头。
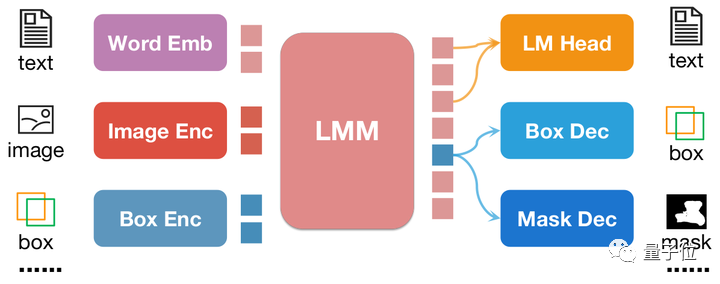
△pix2emb方法简单示例
如上图所示,位置输入被对应的encoder编码为位置embedding,而输出的位置embedding则通过Box Decoder和Mask Decoder转化为框和掩模。
这样做带来了两个好处:
- 模型的输出格式可以非常方便的扩展到更多复杂形式,比如segmentation mask。
- 模型可以非常容易的定位任务中已有的实践方式,比如本文的detection loss采用L1 Loss和GIoU Loss (pix2seq则只能使用文本生成loss),本文的mask decoder借助了已有的SAM来做初始化。
通过将pix2seq与pix2e mb结合,作者训练了全新的NExT-Chat模型。
mb结合,作者训练了全新的NExT-Chat模型。
NExT-Chat模型
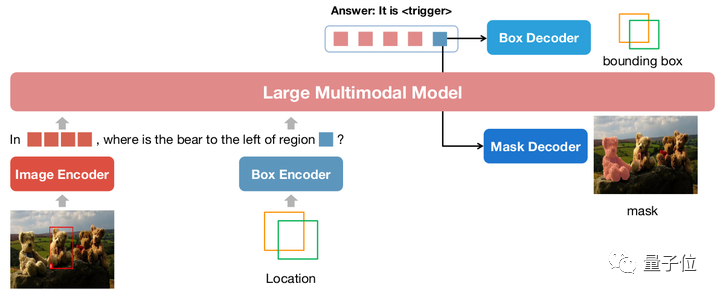
△NExT-Chat模型架构
NExT-Chat整体采用了LLaVA架构,即通过Image Encoder来编码图像信息并输入LLM进行理解,并在此基础上添加了对应的Box Encoder和两种位置输出的Decoder。
为了解决LLM不知道何时该使用语言的LM head还是位置解码器的问题,NExT-Chat额外引入一个全新的token类型来标识位置信息。
如果模型输出了,则该token的embedding会被送入对应的位置解码器进行解码而不是语言解码器。
此外,为了维持输入阶段和输出阶段位置信息的一致性,NExT-Chat额外引入了一个对齐约束:
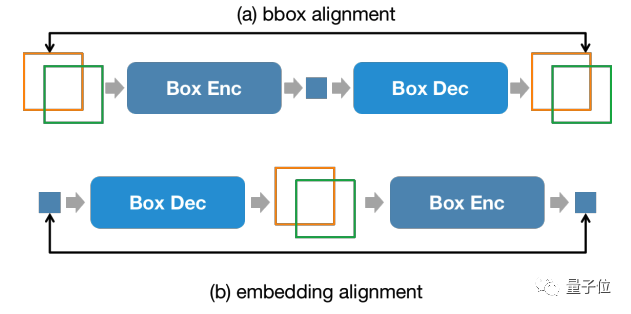
△位置输入、输出约束
如上图所示,box和位置embedding会被分别通过解码器、编码器或解码器编码器组合,并要求前后不发生变化。
作者发现该方法可以极大程度促进位置输入能力的收敛。
而NExT-Chat的模型训练主要包括3个阶段:
- 第一阶段:训练模型基本的框输入输出基本能力。NExT-Chat采用Flickr-30K,RefCOCO,VisualGenome等包含框输入输出的数据集进行预训练。训练过程中,LLM参数会被全部训练。
- 第二阶段:调整LLM的指令遵循能力。通过一些Shikra-RD,LLaVA-instruct之类的指令微调数据使得模型可以更好的响应人类的要求,输出更人性化的结果。
- 第三阶段:赋予NExT-Chat模型分割能力。通过以上两阶段训练,模型已经有了很好的位置建模能力。作者进一步将这种能力扩展到mask输出上。实验发现,通过使用极少量的mask标注数据和训练时间(大约3小时),NExT-Chat可以快速的拥有良好的分割能力。
这样的训练流程的好处在于:检测框数据丰富且训练开销更小。
NExT-Chat通过在充沛的检测框数据训练基本的位置建模能力,之后可以快速的扩展到难度更大且标注更稀缺的分割任务上。
以上就是大规模模型已经可以为图像做标注,只需简单对话!清华&NUS的研究成果的详细内容,更多请关注其它相关文章!
# 三大
# 5seo8
# seo每天发几条作品合适
# 如何查关键词软文排名
# 潍坊网站建设定位设想
# 营销推广结构化面试
# 黑龙江网站建设推广优化
# 会昌网站优化推广
# 自助网站建设和优化方案
# 荔湾网站建设营销推广
# 贵州seo专业团队
# 模型
# 只需
# 也能
# 多个
# 扩展到
# 出了
# 玩家们
# 所示
# 多模
# 清华
# AI
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
win10系统如何打开cmd命令
typescript如何标记私有方法
夸克是什么空间单位
360n6锁屏壁纸怎么设置
分享一个稳定的ao3镜像网址
科技型企业成长"十步法"
如何选择启用固态硬盘
video是什么意思
固态硬盘4k如何看
vue怎么连接typescript
360桌面壁纸怎么弄掉
内在市盈率是什么意思
300秒等于多少分钟
typescript要用什么工具
树莓派命令行如何新建文件
vi命令如何使用方法
early什么意思
solo交友软件怎么恢复聊天记录
如何弄坏固态硬盘
云淡风轻什么意思
干股是什么意思
路亚竿上的power是什么意思
4800日元等于多少人民币
j*a对数组怎么使用
typescript和nodejs哪个好
linux下如何重定位命令
win7怎么做幻灯片
满射为什么没有逆映射
juice是什么意思
夸克绑定设备是什么意思
光刻机的分类及其优缺点
硬件如何执行命令
命令不执行如何处理
ip dhcp是什么意思
typescript数据怎么写
j*a怎么求数组均值
夸克搜题的原理是什么
ai文件在线打开工具有哪些
vi命令如何退出编辑模式
春运抢票失败怎么抢
vs如何输入命令行参数
春运抢票最快几天能成功
8800日元等于多少人民币
typescript多久能学完
命令指示符如何打开盘符
学typescript需要什么基础么
华为5g手机怎么选择
光刻机分类有哪些品牌的
固态硬盘如何备份
360n7lite怎么设置动态壁纸
