









新闻中心 
使用GaLore在本地GPU进行高效的LLM调优
 2024-03-26
2024-03-26 浏览次数:次
浏览次数:次 返回列表
返回列表训练大型语言模型(llm)是一项计算密集型的任务,即使是那些“只有”70亿个参数的模型也是如此。这种级别的训练需要的资源超出了大多数个人爱好者的能力范围。为了弥补这一差距,出现了低秩适应(lora)等参数高效方法,使得在消费级gpu上可以对大量模型进行微调。
GaLore是一种创新方法,它采用优化参数训练方式来减少VRAM需求,而非简单减少参数数量。这意味着GaLore是一种新的模型训练策略,允许模型充分利用全部参数进行学习,并比LoRA更有效地节省内存。
GaLore通过将这些梯度映射到低维空间,有效减轻了计算负担,同时保留了关键的训练信息。与传统优化器在反向传播时一次性更新所有层不同,GaLore采用逐层更新的方式进行反向传播。这种策略显著减少了训练过程中的内存占用,进一步优化了性能。
就像LoRA一样,GaLore使我们能够在消费级GPU上微调7B模型,该GPU配备了高达24 GB的VRAM。结果显示,模型的性能与全参数微调相当,甚至似乎优于LoRA。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
优于目前Hugging Face还没有官方代码,我们就来手动使用论文的代码进行训练,并与LoRA进行对比
安装依赖
首先就要安装GaLore
pip install galore-torch
然后我们还要一下这些库,并且请注意版本
datasets==2.18.0 transformers==4.39.1 trl==0.8.1 accelerate==0.28.0 torch==2.2.1
调度器和优化器的类
Galore分层优化器是通过模型权重挂钩激活的。由于我们使用Hugging Face Trainer,还需要自己实现一个优化器和调度器的抽象类。这些类的结构不执行任何操作。
from typing import Optional import torch # Approach taken from Hugging Face transformers https://github.com/huggingface/transformers/blob/main/src/transformers/optimization.py class LayerWiseDummyOptimizer(torch.optim.Optimizer):def __init__(self, optimizer_dict=None, *args, **kwargs):dummy_tensor = torch.randn(1, 1)self.optimizer_dict = optimizer_dictsuper().__init__([dummy_tensor], {"lr": 1e-03}) def zero_grad(self, set_to_none: bool = True) -> None: pass def step(self, closure=None) -> Optional[float]: pass class LayerWiseDummyScheduler(torch.optim.lr_scheduler.LRScheduler):def __init__(self, *args, **kwargs):optimizer = LayerWiseDummyOptimizer()last_epoch = -1verbose = Falsesuper().__init__(optimizer, last_epoch, verbose) def get_lr(self): return [group["lr"] for group in self.optimizer.param_groups] def _get_closed_form_lr(self): return self.base_lrs
 nsor = torch.randn(1, 1)self.optimizer_dict = optimizer_dictsuper().__init__([dummy_tensor], {"lr": 1e-03}) def zero_grad(self, set_to_none: bool = True) -> None: pass def step(self, closure=None) -> Optional[float]: pass class LayerWiseDummyScheduler(torch.optim.lr_scheduler.LRScheduler):def __init__(self, *args, **kwargs):optimizer = LayerWiseDummyOptimizer()last_epoch = -1verbose = Falsesuper().__init__(optimizer, last_epoch, verbose) def get_lr(self): return [group["lr"] for group in self.optimizer.param_groups] def _get_closed_form_lr(self): return self.base_lrs
nsor = torch.randn(1, 1)self.optimizer_dict = optimizer_dictsuper().__init__([dummy_tensor], {"lr": 1e-03}) def zero_grad(self, set_to_none: bool = True) -> None: pass def step(self, closure=None) -> Optional[float]: pass class LayerWiseDummyScheduler(torch.optim.lr_scheduler.LRScheduler):def __init__(self, *args, **kwargs):optimizer = LayerWiseDummyOptimizer()last_epoch = -1verbose = Falsesuper().__init__(optimizer, last_epoch, verbose) def get_lr(self): return [group["lr"] for group in self.optimizer.param_groups] def _get_closed_form_lr(self): return self.base_lrs加载GaLore优化器
GaLore优化器的目标是特定的参数,主要是那些在线性层中以attn或mlp命名的参数。通过系统地将函数与这些目标参数挂钩,GaLore 8位优化器就会开始工作。
from transformers import get_constant_schedule from functools import partial import torch.nn import bitsandbytes as bnb from galore_torch import GaLoreAdamW8bit def load_galore_optimizer(model, lr, galore_config):# function to hook optimizer and scheduler to a given parameter def optimizer_hook(p, optimizer, scheduler):if p.grad is not None: optimizer.step()optimizer.zero_grad()scheduler.step() # Parameters to optimize with Galoregalore_params = [(module.weight, module_name) for module_name, module in model.named_modules() if isinstance(module, nn.Linear) and any(target_key in module_name for target_key in galore_config["target_modules_list"])] id_galore_params = {id(p) for p, _ in galore_params} # Hook Galore optim to all target params, Adam8bit to all othersfor p in model.parameters():if p.requires_grad:if id(p) in id_galore_params:optimizer = GaLoreAdamW8bit([dict(params=[p], **galore_config)], lr=lr)else:optimizer = bnb.optim.Adam8bit([p], lr = lr)scheduler = get_constant_schedule(optimizer) p.register_post_accumulate_grad_hook(partial(optimizer_hook, optimizer=optimizer, scheduler=scheduler)) # return dummies, stepping is done with hooks return LayerWiseDummyOptimizer(), LayerWiseDummyScheduler()
HF Trainer
准备好优化器后,我们开始使用Trainer进行训练。下面是一个简单的例子,使用TRL的SFTTrainer (Trainer的子类)在Open Assistant数据集上微调llama2-7b,并在RTX 3090/4090等24 GB VRAM GPU上运行。
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, set_seed, get_constant_schedule from trl import SFTTrainer, setup_chat_format, DataCollatorForCompletionOnlyLM from datasets import load_dataset import torch, torch.nn as nn, uuid, wandb lr = 1e-5 # GaLore optimizer hyperparameters galore_config = dict(target_modules_list = ["attn", "mlp"], rank = 1024, update_proj_gap = 200, scale = 2, proj_type="std" ) modelpath = "meta-llama/Llama-2-7b" model = AutoModelForCausalLM.from_pretrained(modelpath,torch_dtype=torch.bfloat16,attn_implementation = "flash_attention_2",device_map = "auto",use_cache = False, ) tokenizer = AutoTokenizer.from_pretrained(modelpath, use_fast = False) # Setup for ChatML model, tokenizer = setup_chat_format(model, tokenizer) if tokenizer.pad_token in [None, tokenizer.eos_token]: tokenizer.pad_token = tokenizer.unk_token # subset of the Open Assistant 2 dataset, 4000 of the top ranking conversations dataset = load_dataset("g-ronimo/oasst2_top4k_en") training_arguments = TrainingArguments(output_dir = f"out_{run_id}",evaluation_strategy = "steps",label_names = ["labels"],per_device_train_batch_size = 16,gradient_accumulation_steps = 1,s*e_steps = 250,eval_steps = 250,logging_steps = 1, learning_rate = lr,num_train_epochs = 3,lr_scheduler_type = "constant",gradient_checkpointing = True,group_by_length = False, ) optimizers = load_galore_optimizer(model, lr, galore_config) trainer = SFTTrainer(model = model,tokenizer = tokenizer,train_dataset = dataset["train"],eval_dataset = dataset['test'],data_collator = DataCollatorForCompletionOnlyLM(instruction_template = "<|im_start|>user", response_template = "<|im_start|>assistant", tokenizer = tokenizer, mlm = False),max_seq_length = 256,dataset_kwargs = dict(add_special_tokens = False),optimizers = optimizers,args = training_arguments, ) trainer.train()
GaLore优化器带有一些需要设置的超参数如下:
target_modules_list:指定GaLore针对的层
rank:投影矩阵的秩。与LoRA类似,秩越高,微调就越接近全参数微调。GaLore的作者建议7B使用1024
 企业网站管理系统YothCMS 1.0 修正版
企业网站管理系统YothCMS 1.0 修正版
YothCMS是由 石家庄优斯科技有限公司开发的一套完全开源建站系统,主要面向企业进行快速的建造简洁,高效,易用,安全的公司企业网门户站,稍具技术的开发人员就能够使用本系统以最低的成本、最少的人力投入在最短的时间内架设一个功能齐全、性能优越的公司企业网站。YothCMS是基于ASP+Access开发的一款轻巧高效的网站内容管理系统,提供了新闻管理模块,产品管理模块,文件管理模块。在使用过程中可以轻
 0
查看详情
0
查看详情

update_proj_gap:更新投影的步骤数。这是一个昂贵的步骤,对于7B来说大约需要15分钟。定义更新投影的间隔,建议范围在50到1000步之间。
scale:类似于LoRA的alpha的比例因子,用于调整更新强度。在尝试了几个值之后,我发现scale=2最接近于经典的全参数微调。
微调效果对比
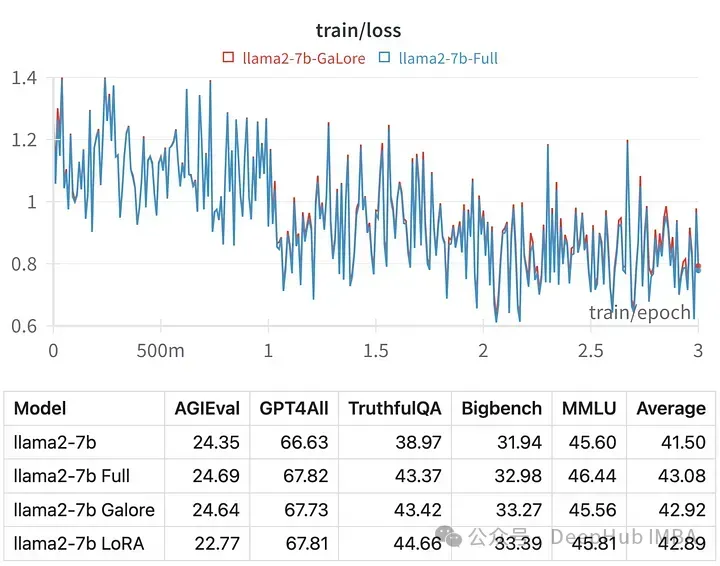
给定超参数的训练损失与全参数调优的轨迹非常相似,表明GaLore分层方法确实是等效的。
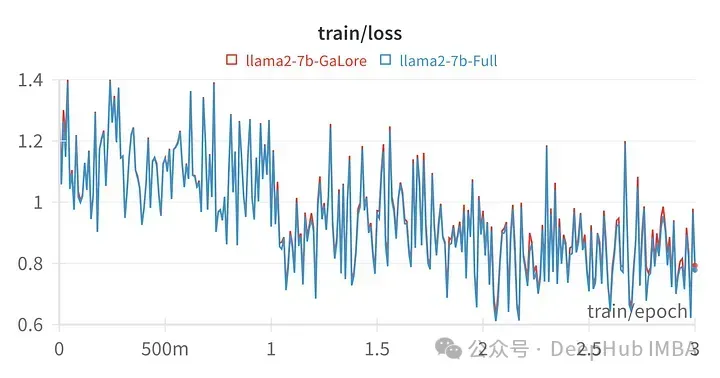
用GaLore训练的模型得分与全参数微调非常相似。
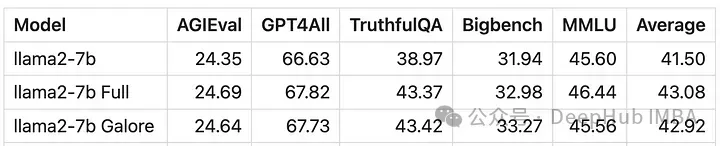
GaLore可以节省大约15 GB的VRAM,但由于定期投影更新,它需要更长的训练时间。
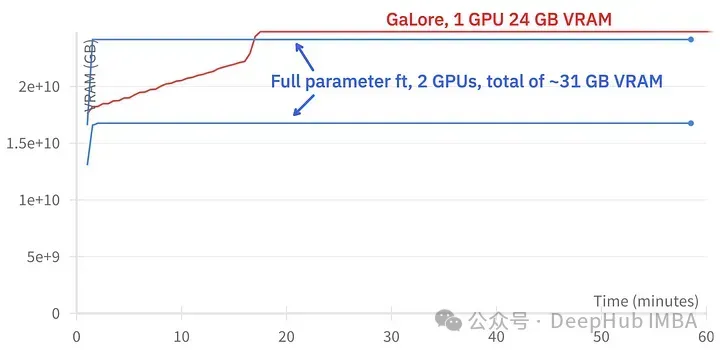
上图为2个3090的内存占用对比
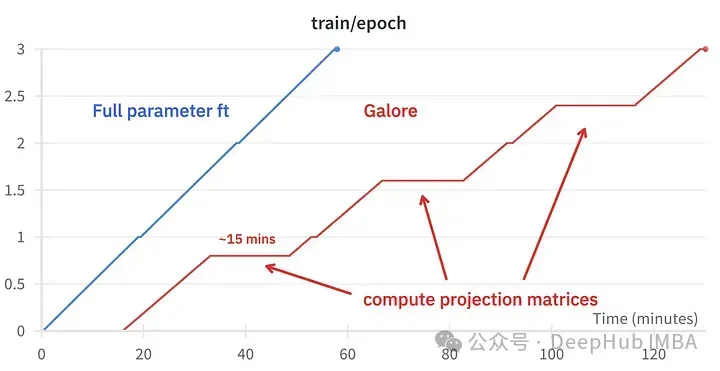
训练事件对比,微调:~58分钟。GaLore:约130分钟
最后我们再看看GaLore和LoRA的对比
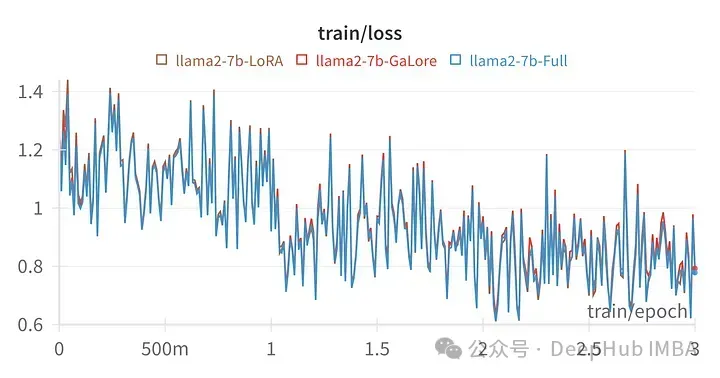
上图为LoRA微调所有线性层,rank64,alpha 16的损失图
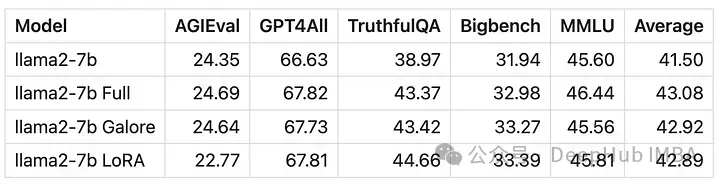
从数值上可以看到GaLore是一种近似全参数训练的新方法,性能与微调相当,比LoRA要好得多。
总结
GaLore可以节省VRAM,允许在消费级GPU上训练7B模型,但是速度较慢,比微调和LoRA的时间要长差不多两倍的时间。
以上就是使用GaLore在本地GPU进行高效的LLM调优的详细内容,更多请关注其它相关文章!
# galore
# 都能
# 开源
# 省电
# 修正版
# 子类
# 是一种
# 企业网站
# type
# fig
# llama
# hugging face
# 内存占用
# 大型语言模型
# 管理系统
# 宁陵专业网站优化推广seo电话
# 海澜之家营销推广工作
# e cigarette 的推广网站
# 三喜网站怎么做推广的
# 推广代码网站案例分享
# 湖南创意seo推荐
# 莱芜网站seo哪家强
# 做百度关键词排名
# 丽水网站建设及优化
# 寒食翻译网站建设需要
# 管理模块
# 腾讯
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
如何打开win10命令
win7怎么装扫描仪
如何用adb命令停用系统软件
春运哪天抢票最好
路由器上的power按钮是什么意思
怎么看手机是不是双模5g手机
typescript解决了什么
npm如何声明命令
如何进入 dos 命令行
typescript学会要多久
手机拍显示屏有条纹怎么去除
硬盘和固态硬盘如何区分
哪些编程软件需用typescript
单片机引脚怎么改成上拉
hive中datediff函数怎么用 Hive中DATEDIFF函数的使用指南
如何自己加装固态硬盘
put linux命令如何书写
typescript能干什么
苹果16哪些型号好
typescript用在哪里
faq是什么意思
显示器的power是什么意思
苹果16有哪些改善
市盈率百分位roe是什么意思
如何退出数据库命令行
东芝固态硬盘如何保修
公司的tm市盈率为负是什么意思
2025年国外最佳语音聊天软件排行榜
折叠屏手机为什么没火
typescript多久能学会
油电混动车仪表盘上的power是什么意思
wps中datediff函数怎么用 WPS中DATEDIFF函数的语法和用法分享
分销是什么意思
路由器上面的power红灯是什么意思
shell如何执行sql脚本命令行
type-c输入接口是什么
春运车站抢票和网上抢票
宵衣旰食是什么意思
如何区别固态硬盘
win10如何打开dos命令窗口大小
ts什么意思
iPhone无法打开YouTube原因分析与解决方案
如何看固态硬盘信息
电瓶车屏幕上显示power是什么意思
typescript多久能学完
vivo手机nfc功能是什么意思
dos命令如何复制目录结构
通配符的用法
华为如何面对苹果16
nosql数据库的应用场景有哪些
