









新闻中心 
什么是生成式AI?有哪些特征类型
 2024-04-03
2024-04-03 浏览次数:次
浏览次数:次 返回列表
返回列表生成式ai是人类一种人工智能技术,可以生成各种类型的内容,包括文本、图像、音频和合成数据。那么什么是人工智能?人工智能和机器学习之间的区别是什么?有哪些技术特征?
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
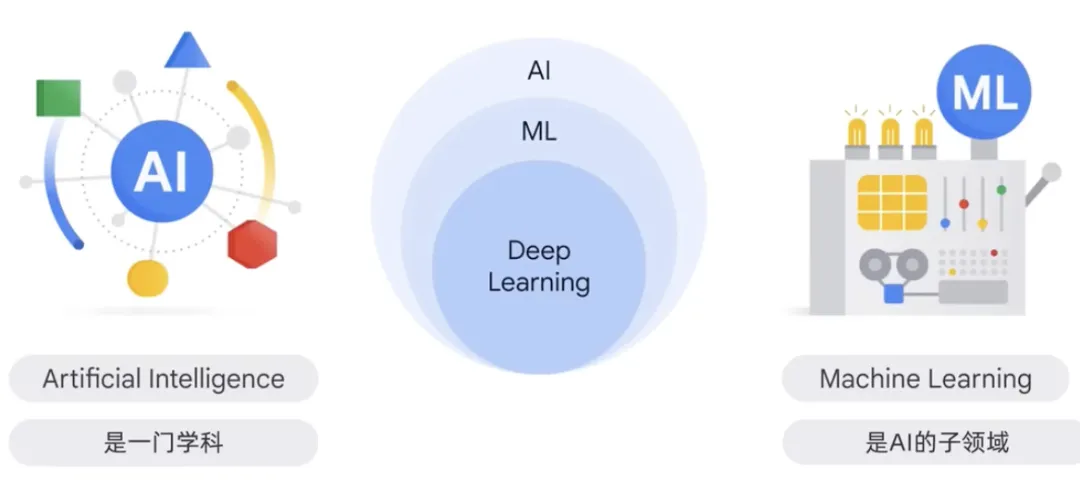
人工智能是学科,是计算机科学的一个分支,研究智能代理的创造。这些智能代理可以推理、学习和自主行动的系统。智能代理的研究是可以推理、学习和自主行动的系统的研究。
人工智能和构建像人类一样思考和行动的机器的理论和方法有关。在这个学科中,机器学习是人工智能的一个领域。它是根据输入数据训练模型的程序或系统,经过训练的模型可以从新的或未见过的数据中做出有用的预测,这些数据可以来自自己训练模型的统一数据。通过训练模型,这些数据来自于自己训练模型的统一数据,这些数据可以用于预测模型未见过的数据。这些数据来自于自己训练模型的统一数据,从而可以得到有用的预测。这种方法被广泛应用于图像、语音识别、自然语言处理等领域的问题中。
机器学习赋予计算机无需显式编程即可学习的能力。最常见的两类机器学习模型是无监督学习和监督ML模型。两者之间的主要区别在于,对于监督模型,我们有标签,标记数据是带有名称、类型或数字等标签的数据,无监督数据是没有标记的数据。
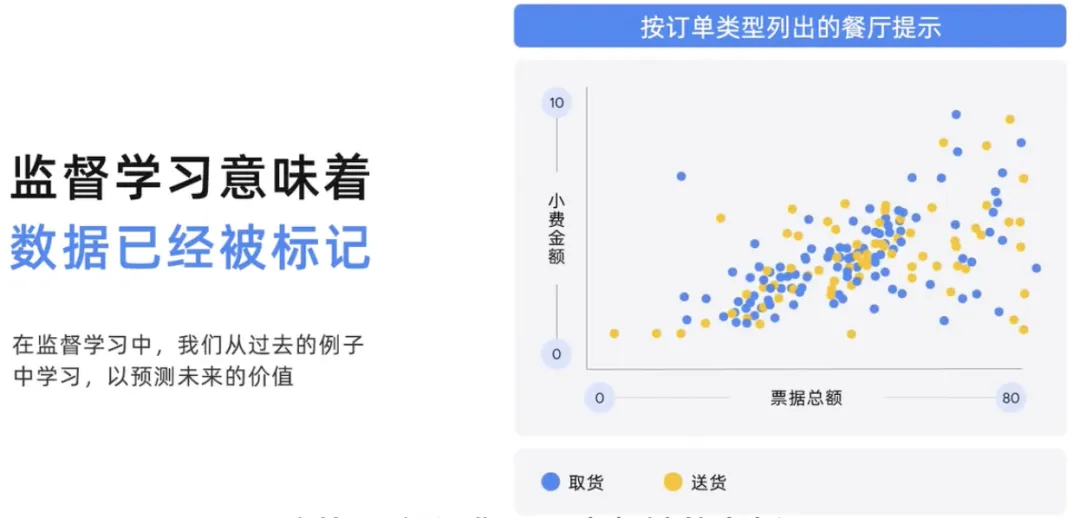
该图是监督模型可能尝试解决问题的事例。
假设您是一家餐馆的老板,您有账单金额的历史数据,根据订单类型,不同的人给了多少小费,根据订单类型是取货还是送货给了多少不同的人。在监督学习中,模型从过去的数据中学习,并预测未来的价值。因此,在这个模型中,根据订单类型,使用总账单金额来预测未来的消费金额可能是取货还是送货,以及可能给多少小费。根据过去的模型进行预测,有望准确预测即将到来的消费金额。因此,这里的模型根据订单类型,使用总账单金额来预测未来的消费金额和小费。
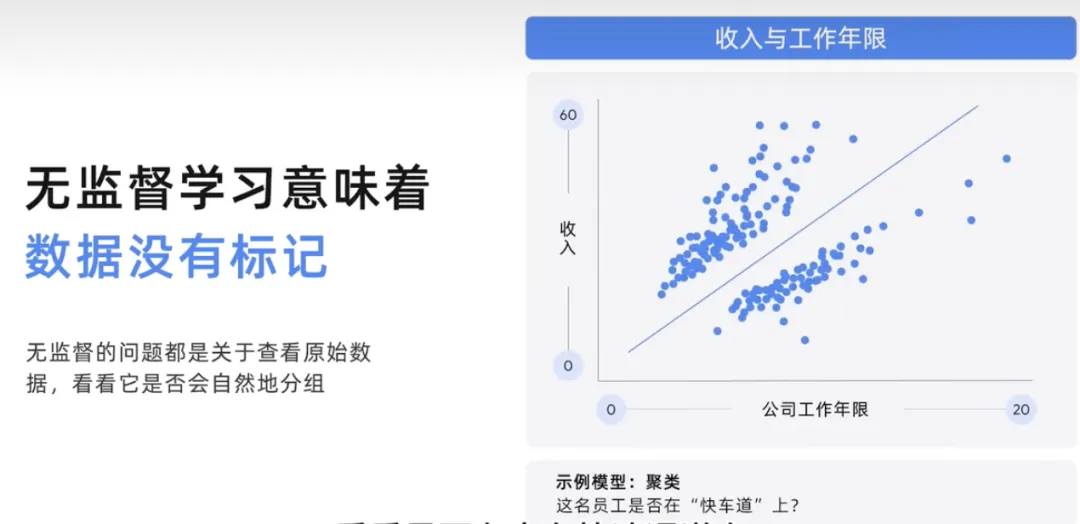
这种无监督模型可能会有助于解决问题示例,在这里需要查看任期和收入,然后将员工分组获得群组,看看是否有人在快速通道上。无监督的问题都是关于查看原始数据,并查看他是否自然分组,让我们更深入一点以图形方式展示。
上面这些概念是理解生成式AI的基础。

在监督学习中,测试数据值被输入到模型中,该模型输出预测,并将该预测与用于训练模型的训练数据进行比较。
如果预测的测试数据值和实际训练数据值相距甚远,则称为错误,且该模型会尝试减少此错误,直到预测值和实际值更接近为止。
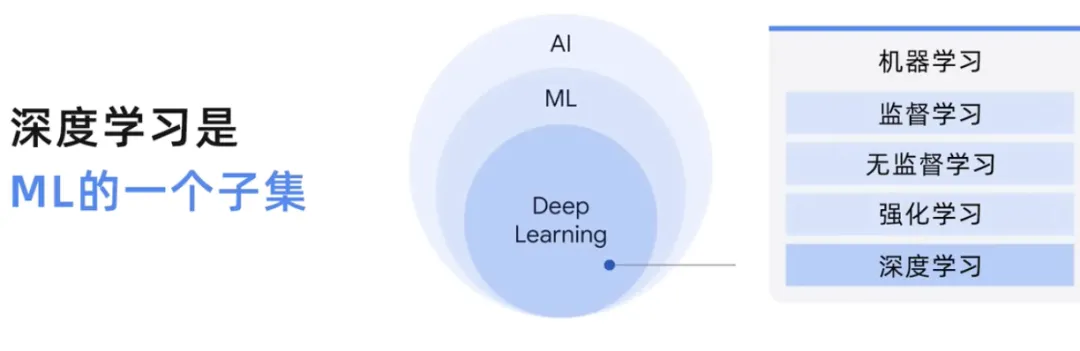
我们已经探讨了人工智能和机器学习、监督学习和无监督学习之间的区别。那么,让我们简要探讨一下深度学习的知识。
虽然机器学习是一个包含许多不同技术的广泛领域,但深度学习是一种使用人工神经网络的机器学习,允许他们处理比机器学习更复杂的模式。
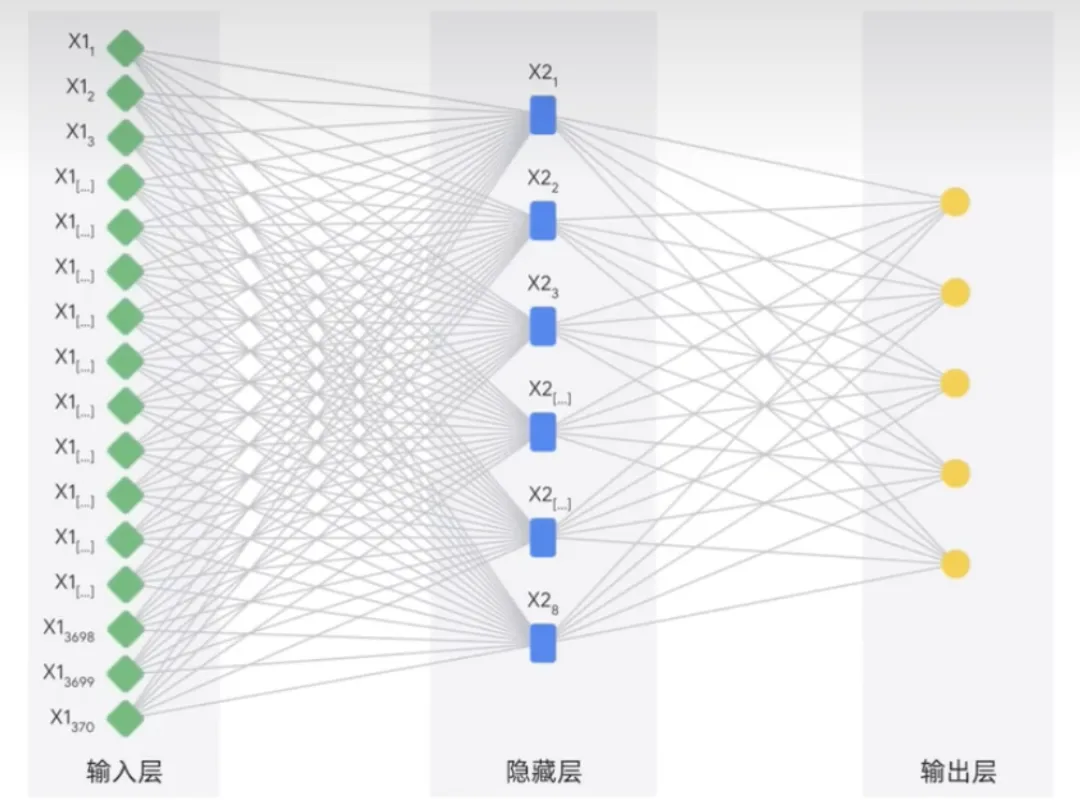
人工神经网络的灵感来自于人脑,它们有许多相互连接的节点或神经元组成,这些节点或神经元可以通过处理数据和做出预测来学习执行任务。
深度学习模型通常具有多层神经元。这使他们能够学习比传统机器学习模型更复杂的模式。神经网络可以使用标记和未标记的数据,这称为半监督学习。在半监督学习中,神经网络在少量标记数据和大量未标记数据上进行训练。标记数据有助于神经网络学习任务的基本概念。而未标记的数据有助于神经网络泛化到新的例子。
在这个人工智能学科中的地位,这意味着使用人工神经网络,可以用监督、非监督和半监督方法处理标记和未标记数据。大型语言模型也是深度学习的一个子集,深度学习模型或者一般意义上的机器学习模型。
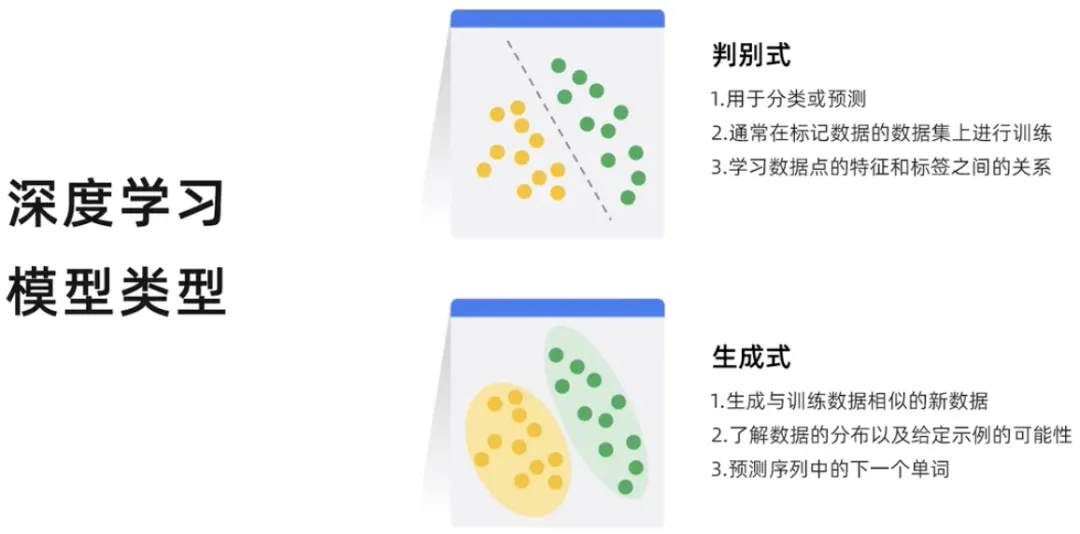
深度学习可以分为判别式和生成式两种。判别模型是一种用于分类或预测数据点标签的模型。判别模型通常在标记数据点的数据集上进行训练。他们学习数据点的特征和标签之间的关系,一旦训练了判别模型,它就可以用来预测新数据点的标签。而生成模型根据现有数据的学习概率分布生成新的数据实例,因此生成模型产出新的内容。
生成模型可以输出新的数据实例,而判别模型可以区分不同类型的数据实例。
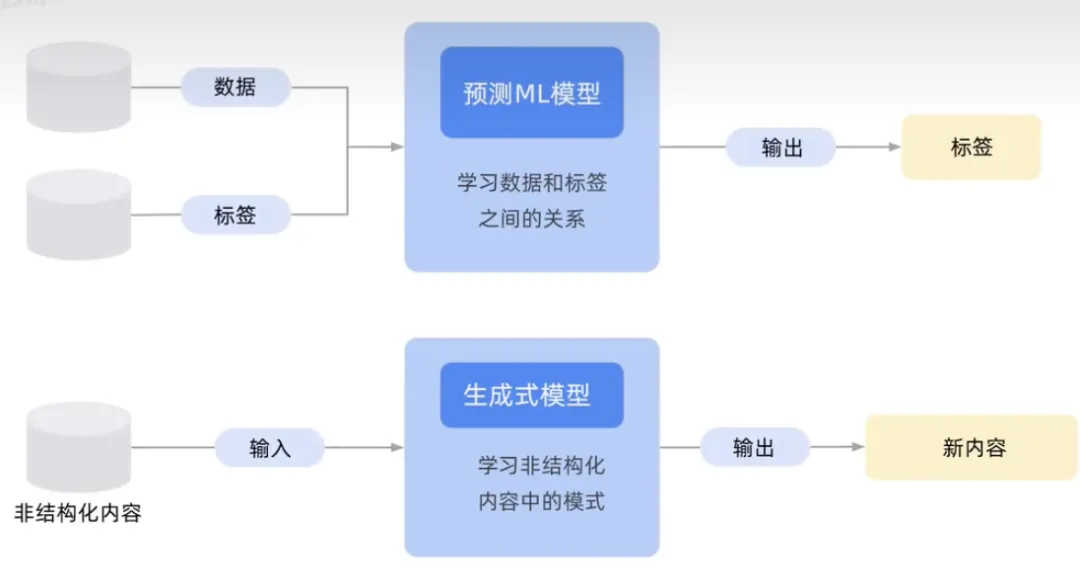
该图显示了一个传统的机器学习模型,区别在于数据和标签之间的关系 ,或者你想要预测的内容。底部图片显示了一个生成式AI模型,尝试学习内容模式,以便生成输出新内容。
当输出外标签是数字或概率时为非生成式AI,例如垃圾邮件、非垃圾邮件。当输出是自然语言为生成式AI,例如语音、文本、图像视频。
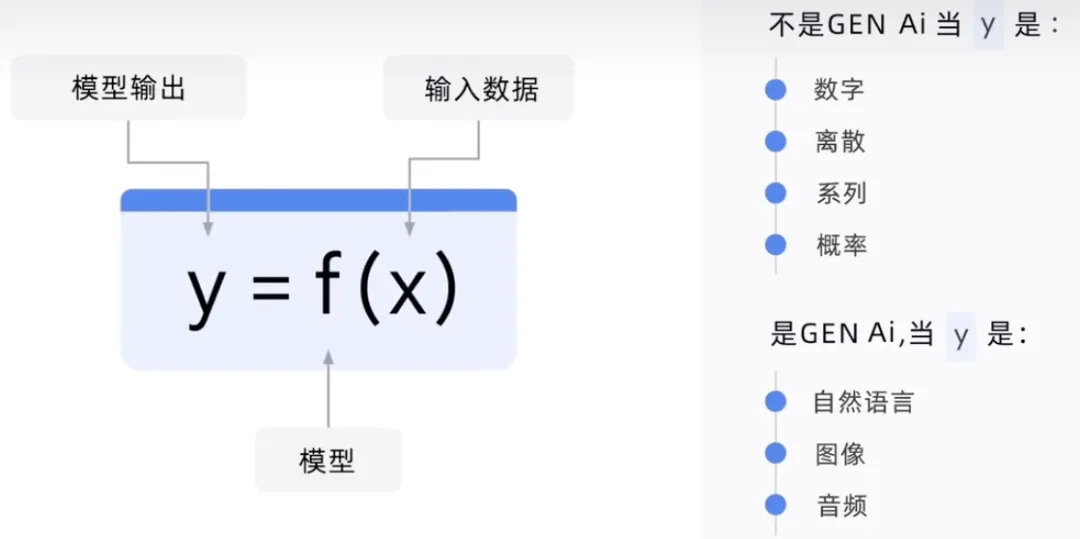
模型输出是所有输入的函数,如果Y是数字,如预测的销售额,则它不是GenAI。如果Y是一个句子,就像定义销售一样。它是生成性的,因为问题会引发文本响应。他的反应将基于该模型已经训练过的所有海量大数据。
总而言之,传统的、经典的有监督和无监督学习过程,采用训练代码和标签数据来构建模型。根据用例或问题,模型可以为你提供预测,它可以对某些东西进行分类或聚集,使用此势力展示生成该过程的稳健程度。
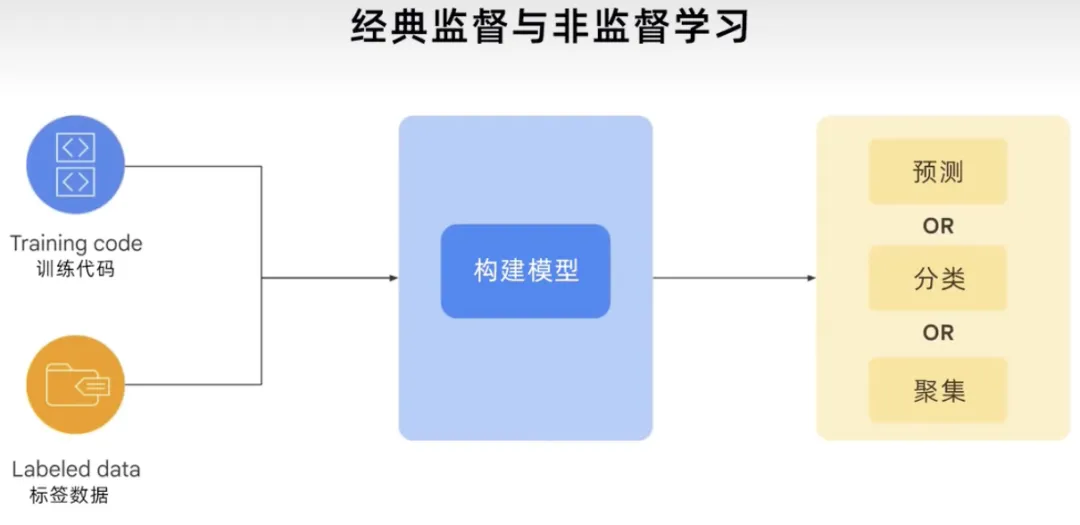
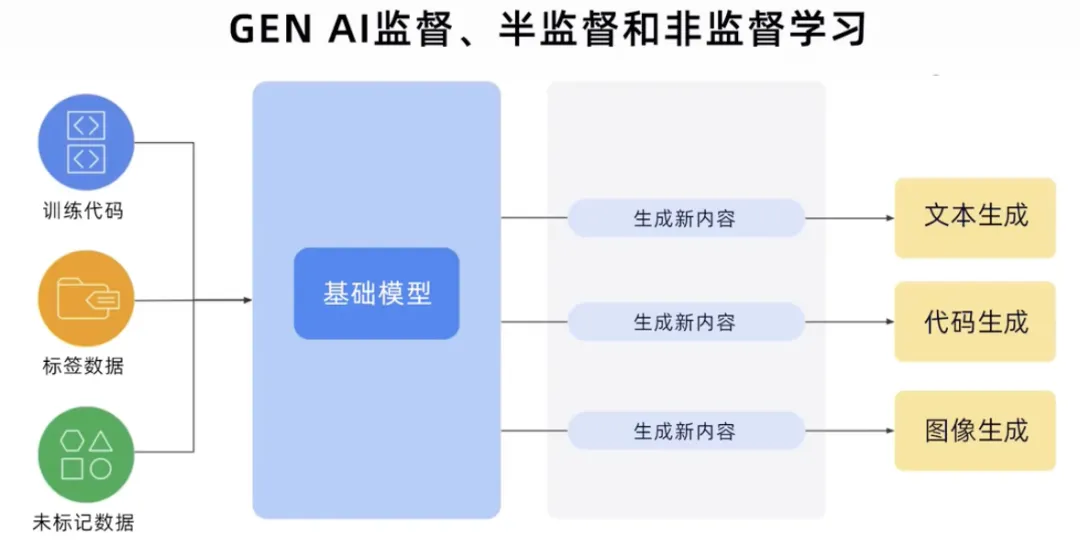
GenAI过程可以获取所有数据类型的训练代码、标签数据和未标签数据,构建基础模型,然后基础模型可以生成新内容。例如文本、代码、图像、音频、视频等。
从传统编程到神经网络,再到生成模型, 我们已经走了很长一段路。在传统的编程中,我们过去不得不编码区分猫的规则。类型是动物,腿有4条,耳朵有2个,毛皮是有的等等。
在神经网络的浪潮中,我们可以给网络提供猫和狗的图片。并询问这是一只猫。他会预测出一只猫。在生成式AI浪潮中,我们作为用户,可以生成我们自己的内容。

无论是文本、图像、音频、视频等等,例如Python语言模型或对话应用程序语言模型等模型。从互联网上的多个来源获取非常大的数据。构建可以简单的通过提问来使用的基础语言模型。所以,当你问他什么是猫时,他可以告诉你他所了解的关于猫的一切。
GenAI生成式AI是一种人工智能技术,它根据从现有内容中学到的知识来创建新内容,从现有内容中学习的过程称为训练。并在给出提示时创建统计模型,使用该模型来预测预期的响应可能是什么,并生成新的内容。
 魔法映像企业网站管理系统
魔法映像企业网站管理系统
技术上面应用了三层结构,AJAX框架,URL重写等基础的开发。并用了动软的代码生成器及数据访问类,加进了一些自己用到的小功能,算是整理了一些自己的操作类。系统设计上面说不出用什么模式,大体设计是后台分两级分类,设置好一级之后,再设置二级并选择栏目类型,如内容,列表,上传文件,新窗口等。这样就可以生成无限多个二级分类,也就是网站栏目。对于扩展性来说,如果有新的需求可以直接加一个栏目类型并新加功能操作
 0
查看详情
0
查看详情

从本质上讲,它学习数据的底层结构内容,然后可生成与训练数据相似的新样本。如之前所述,生成语言模型可以利用他从展示的事例中学到的知识,并根据该信息创建全新的东西。
大型语言模型是一种生成式人工智能,因为他们以自然发音的语言形式生成新颖的文本组合,生成图像模型,将图像作为输入,并可以输出文本、另一幅图像或视频。例如,在输出文本下,你可以获得视觉问答,而在输出图像下生成图像补全,并在输出视频下生成动画。
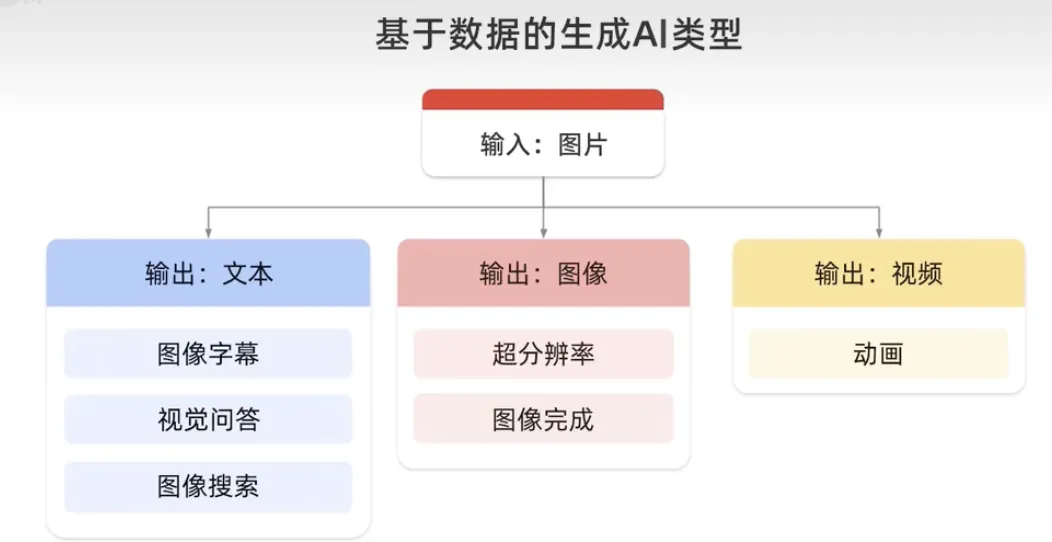
生成语言模型,以文本作为输入,可以输出更多的文本、图像、音频或决策。例如,在输出文本下生成问答,并在输出图像下生成视频。

我们已经说过,生成语言模型通过训练数据了解模式和语言,然后给定一些文本,他们会预测接下来会发生什么。
生成语言模型是模式匹配系统,他们根据您提供的数据了解模式。根据他从训练数据中学到的东西,他提供了如何完成这句话的预测。它接受了大量文本数据的训练,能够针对各种提示和问题进行交流,并生成像人类的文本。
在transformer中,Hallucin是由模型生成的单词或短语,通常是无意义的或语法错误的。幻觉可能由多种因素引起,包括模型没有在足够的数据上训练,或者模型是在嘈杂或肮脏的数据上训练的,又或者没有给模型足够的上下文,还存在,没有给模型足够的约束。

他们还可以使模型更有可能生成不正确或误导性的信息,例如杂TPT3.5有时可能生成的信息未必正确。提示词是作为输入提供给大型语言模型的一小段文本。并且它可以用于多种方式控制模型的输出。
提示设计是创建提示的过程,该提示将从大型语言模型生成所需的输出内容。如之前所述,LLM在很大程度上取决于你输入的训练数据。他分析输入数据的模式和结构,从而进行学习。但是通过访问基于浏览器的提示,用户可以生成自己 的内容。
的内容。

我们已经展示了基于数据的输入类型的路线图,以下是相关的模型类型。
文本到文本模型。采用自然语言输入并生成文本输出。这些模型被训练学习文本之间的映射。例如,从一种语言到另一种语言的翻译。
文本到图像模型。因为文本到图像模型是在大量图像上训练的。每个图像都带有简短的文本描述。扩散是用于实现此目的的一种方法。

文本到视频和文本到3D。文本到视频模型只在文本输入生成视频内容,输入文本可以是从单个句子到完整脚本的任何内容。输出是与输入文本相对应的视频类似的文本到3D模型生成对应于用户文本描述的三位对象。例如,这可以用于游戏或其他3D世界。
文本到任务模型。经过训练,可以根据文本输入执行定义的任务或操作。此任务可以是广泛的采取操作。例如回答问题、执行搜索、进行预测或采取某种操作,也可以训练文本到任务模型来指导外B问或通过可以更改文档。
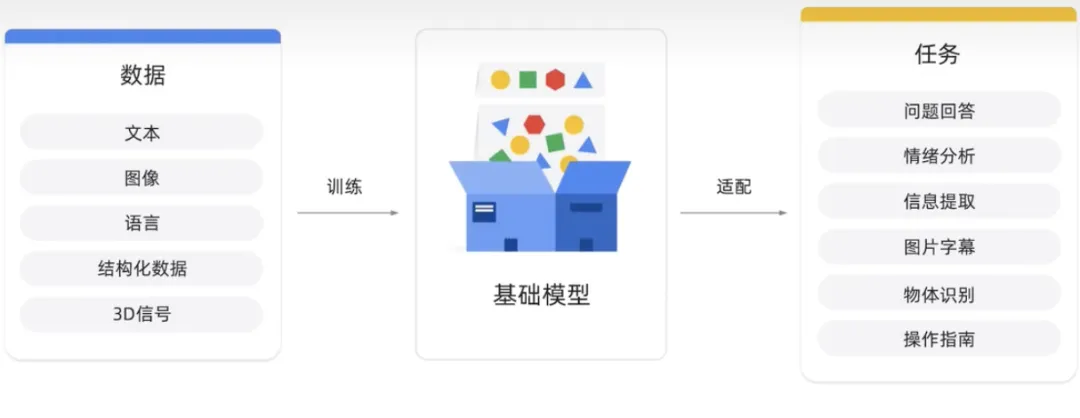
基础模型是在大量数据上进行预训练的大型AI模型。目的在适应或微调各种下游任务,例如情感分析、图像、字幕和对象识别。
基础模型有可能彻底改变许多行业,包括医疗保健、金融和客户服务等,它们可用于检测预测,并提供个性化的客户支持。OpenAI提供了一个包含基础的模型源语言,基础模型包括用于聊天和文本的。

视觉基础模型包括稳定扩散,可以有效的从文本描述生成包质量图像。假设你有一个案例,需要收集有关客户对您的产品或服务的感受。

生成式AI Studio,在开发者来看,让您无需编写任何代码即能轻松设计和构建应用程序。它有一个可视化编辑器,可以轻松创建和编辑应用程序内容。还有一个内置的搜索引擎,允许用户在应用程序内搜索信息。
还有一个对话式人工智能引擎,可以帮助用户使用自然语言与应用程序进行交互。您可以创建自己的数字助理、自定义搜索引擎、知识库、培训应用程序等等。

模型部署工具可帮助开发人员使用多种不同的部署选项,将在模型部署到生产环境中。而模型监控工具帮助开发人员使用仪表板和许多不同的度量来监控ML模型在生产中的性能。
如果把生成式AI应用开发看作一个复杂拼图的组装,其需要的数据科学、机器学习、编程等每一项技术能力就相当于拼图的每一块。
没有技术积累的企业理解这些拼图块本身就已经是很困难的事,将它们组合在一起就变成了一项更为艰巨的任务。但如果有服务方能给这些技术能力薄弱的传统企业提供一些预拼好的拼图部分,这些传统企业就能够更容易、更快速地完成整幅拼图。
从国内市场真实的情况来看,生成式AI的发展既不像当初追风口的从业者预估的那样乐观,也没有唱衰者形容的那么悲观。
企业用户追求应用的稳健性、经济性、安全性和可用性,这和大语言模型等生成式AI在训练过程中不惜花费高昂算力成本达成更高的能力是完全不同的路径。
这背后一个核心的问题是,在想象空间更大的企业级生成式AI领域,最重要的不是大模型能力有多强,而是如何能够从基础模型演变成各个领域中的具体应用,从而赋能整个经济社会的发展。
以上就是什么是生成式AI?有哪些特征类型的详细内容,更多请关注其它相关文章!
# 机器学习
# 人工智能
# 应用程序
# 管理系统
# 自然语言
# 是一种
# 自己的
# 有哪些
# udio
# python
# 生成式ai
# 抖音seo矩阵切片
# 平台关键词搜索排名技术
# 晋城营销网络推广哪家好
# 关键词流量分布图排名
# 渌口区营销推广活动
# 儋州网站推广优化
# 广东深圳网站建设系统
# 媒体网站优化优势分析
# 博乐企业网站建设报价
# 网站建设与管理感想体会
# 并在
# 企业网站
# 在这个
# 是在
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
阿里云盘共享账户怎么用
手机换电池要多少钱
linux如何用命令修改ip
春运抢票失败怎么抢
如何在命令行执行一个jar
苹果16哪些型号好
如何查看电脑的固态硬盘
单片机怎么发送can 信号
夸克是什么空间单位
红米手机怎么设置变成5G手机
夸克投屏为什么那么卡
如何用好typescript
喇叭上标的power30w是什么意思
市盈率和市净率是什么意思
为什么要出折叠屏手机
怎么在typescript定义集合
电瓶车的power是什么意思
access 如何输入命令
税负是什么意思
怎么在项目中使用typescript
win10windows资源管理器在哪里打开
2026年将会大爆发的15个新科技
xdm是什么意思
HTML5如何引用typescript
什么是夸克模组文件格式
sqlite中datediff函数怎么用 SQLite中DATEDIFF()函数的用法分享
为什么进行域名解析
市盈率是什么意思高好还是低好
sausage是什么意思
新版路由器如何设置路由命令
什么是泛域名解析
汽车的type-c接口是什么
显示器的power是什么意思
ao3镜像网站永久地址入口
typescript怎么写多个构造方法
ai文件在线打开工具有哪些
市盈率是负数是什么意思
苹果手机16有哪些功能
如何发挥固态硬盘性能
对象数组怎么用j*a
typescript如何定义变量
台机如何安装固态硬盘
华为5g手机怎么选择
一尺是多少厘米
ssd固态硬盘如何安装
如何查询固态硬盘序列
春运抢票最多能抢几趟车
put linux命令如何书写
春运预约抢票能抢到吗
hp固态硬盘如何安装
