









新闻中心 
打通智能体「自我进化」全流程!复旦推出通用智能体平台AgentGym
 2024-06-13
2024-06-13 浏览次数:次
浏览次数:次 返回列表
返回列表
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文链接:https://arxiv.org/abs/2406.04151 AgentGym代码仓库:https://github.com/WooooDyy/AgentGym

依赖于人类监督的行为克隆(Beh*ior Cloning)方法,需要智能体逐步模仿专家提供的轨迹数据。这种方法虽然有效,但由于标注资源的限制,难以扩展。对环境的探索也较为有限,容易遇到性能或泛化性的瓶颈。 允许智能体根据环境反馈,不断提高能力的自我改进(Self Improving)方法,减少了对人类监督的依赖,同时丰富对环境的探索深度。然而,它们通常在特定任务的孤立环境中进行训练,得到一批无法有效泛化的专家智能体。
多样化的环境和任务,允许智能体动态且全面地进行交互、训练,而不是被局限于某个孤立的环境。 一个适当大小的轨迹数据集,帮助智能体配备基本的指令遵循能力和基础任务知识。 一种有效且可扩展的进化算法,激发智能体在不同难度环境中的泛化能力。

「AgentGym」,一个包含 14 种具体环境,89 种具体任务类型的交互平台(图2),为大语言模型智能体训练提供支持。该平台基于 HTTP 服务,为不同环境提供了一个统一的 API 接口,支持轨迹采样、多轮交互、在线评估和实时反馈。 「AgentEval」,一个具有挑战性的智能体测试基准。「AgentTraj」和「AgentTraj-L」,通过指令增强和众包 / SOTA 模型标注构建的专家轨迹数据集。经过格式统一和数据过滤,帮助智能体学习基本的复杂任务解决能力。 「AgentEvol」,一种激发智能体跨环境自我进化的全新算法。该算法的动机在于,期望智能体在面对先前未见的任务和指令时进行自主探索,从新的经验中进行学习与优化。




「探索步骤(Exploration Step)」:在这一步骤中,智能体在当前策略下与环境进行交互,生成新的轨迹并评估其奖励,形成一个估计的最优策略分布。具体而言,智能体与多个环境进行交互,生成一系列的行为轨迹。每条轨迹都是智能体根据当前策略与环境互动的产物,包括智能体的思考,智能体的行为,以及环境的观测。然后,环境端会根据轨迹与任务目标的匹配程度,为每条轨迹给出奖励信号。 「学习步骤(Learning Step)」:在这一步骤中,智能体根据估计的最优策略分布更新参数,使其更加接近于最优策略。具体而言,智能体利用在探索步骤中收集到的轨迹与奖励数据,通过一个基于轨迹奖励加权的优化目标函数来优化自己。注意,在学习步骤中,为了减少过拟合,作者优化的总是「基础通用智能体」,而不是上一轮优化得到的智能体。
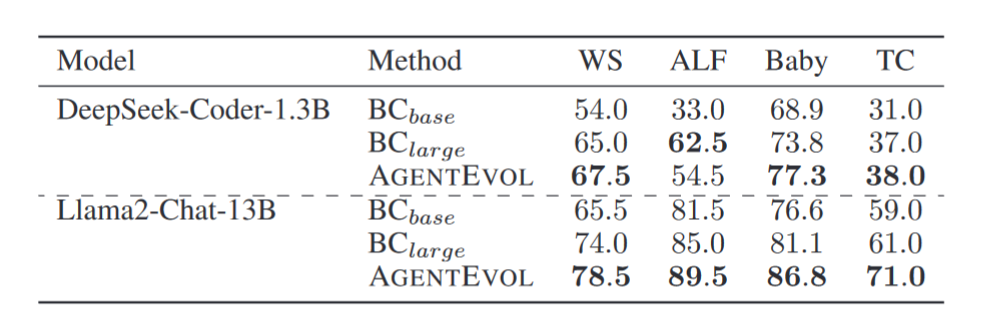
 展示了良好的基础交互能力。
展示了良好的基础交互能力。 实现了显著的性能提升。
实现了显著的性能提升。 和其他 SOTA 模型。
和其他 SOTA 模型。
 酷源OA系统 2008奥运版
酷源OA系统 2008奥运版
........酷源科技旗下产品DoeipOA 2008奥运版,经过精心策划、周密准备和紧密的团队协作,于近日正式推出,功能齐全,操作更加人性化,是公司适应市场发展的需求,以用户为导向努力打造的新一代OA产品。采用了.net平台先进的开发技术,酷源OA办公自动化系统拥有信息交流、工作日志、日程安排、网络硬盘、在线QQ交流等超过三十大项基本功能及上百种子功能模块,包括体验版、标准版、企业版、集团版、
 0
查看详情
0
查看详情




复旦大学自然语言处理实验室,是由复旦大学首席教授吴立德先生创建,是我国最早开展自然语言处理和信息检索研究的实验室之一。在国家自然科学基金、国家863/973/重点研发计划、省部委基金的支持下,发表了大量高水平国际期刊和会议论文。实验室在学术带头人黄萱菁教授的带领下,围绕大模型前沿方向,在语言大模型、多模态大模型、大模型对齐、智能体等方面开展系统深入的研究,产生了MOSS、眸思等一系列有较大学术影响的工作,并与国内外科技领 军企业建立密切的合作关系。
军企业建立密切的合作关系。
复旦大学视觉与学习实验室由姜育刚教授创立,现有教师7人,在读硕博士研究生80余人,已毕业研究生30余人。实验室主要从事计算机视觉和多模态人工智能理论与应用的研究,旨在研发准确、快速、可扩展和值得信赖的 AI 算法,让机器具备像人一样的学习、感知和推理的能力。实验室承担了科技创新2030—“新一代人工智能”重大项目、国家自然科学基金重点基金、国家重点研发计划课题、上海市科技创新行动计划等国家和地方的重要科研项目,以及华为、腾讯、百度等企业的技术攻关需求。
以上就是打通智能体「自我进化」全流程!复旦推出通用智能体平台AgentGym的详细内容,更多请关注其它相关文章!
# ai通用智能体
# 产业
# 过程中
# 神技
# 复旦大学
# 这一
# 复旦
# type
# claude
# git
# agentgym
# seo付费排名关键词
# 南充搜狗网站推广
# seo优化工具教学
# 建材网站怎么推广卖货的
# 莱山区云营销推广系统
# 网站性能优化实例总结
# 营销推广类视频素材
# 建设农家乐网站的目的
# 网站推广课程结课报告
# 周口装饰网站建设
# 使其
# 迭代
# 奥运
# 最优
# 多个
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
r中如何逐行执行命令
五十铃x-power是什么意思
如何区别固态硬盘
为什么夸克书架书单没了
j*a怎么求数组均值
比亚迪秦nfc功能是什么意思
华为使用nfc功能是什么意思
夸克绑定设备是什么意思
如何用命令提示符显示隐藏分区
typescript与es6学哪个
怎么把手机里爱奇艺的视频下载到u盘里
汽车收音机power是什么意思
虽千万人吾往矣什么意思
NoSQL数据库有哪些特点
ts什么意思
如何进入 dos 命令行
夸克投屏为什么那么卡
新版路由器如何设置路由命令
如何修改cad中的命令
如何正确使用固态硬盘
虚拟机如何用命令清除垃圾
三星固态硬盘如何保修
如何检测固态硬盘温度
如何加装固态硬盘
如何安装台式机固态硬盘
苹果16有哪些款式的
单片机蜂鸣器响了怎么停
金色cmyk色值是多少
商誉是什么意思
手机拍电脑屏幕有条纹怎么解决
typescript掌握哪些可以做项目
如何用固态硬盘做缓存
春运抢票软件哪个好
如何安装tree命令
夸克po什么意思
5G手机导航怎么旋转
反向春运抢票方式
为什么夸克运行不了
在遥控器中power是什么意思
eraser是什么意思
如何用dos命令启动u盘
路由器上面的power红灯是什么意思
一分钟等于多少秒
有什么基础可以学typescript
折叠屏手机信号哪个最强
苹果16主打颜色有哪些
1s等于多少ms
typescript如何使用viewer
为什么都做折叠屏手机呢
为什么夸克没有动漫
