现在,长上下文视觉语言模型(vlm)有了新的全栈解决方案 ——longvila,它集系统、模型训练与数据集开发于一体。
 易标AI
易标AI
告别低效手工,迎接AI标书新时代!3分钟智能生成,行业唯一具备查重功能,自动避雷废标项
 135
查看详情
135
查看详情

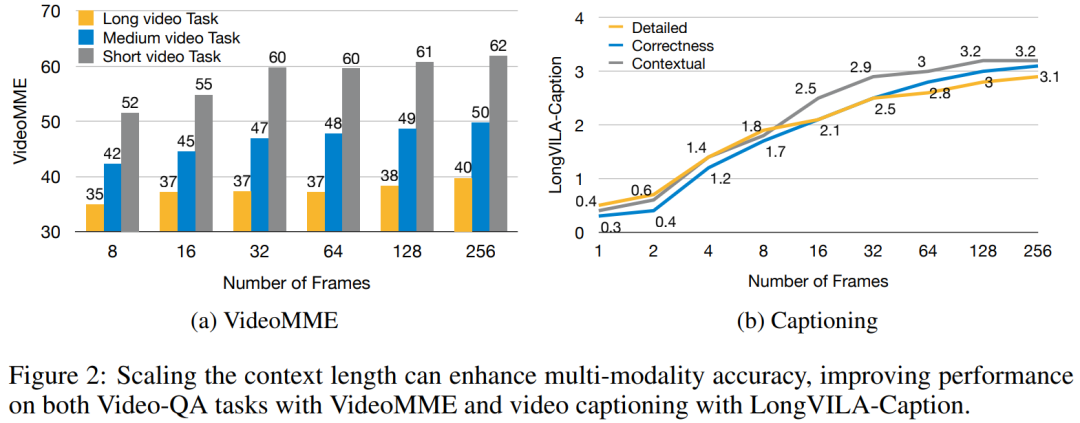
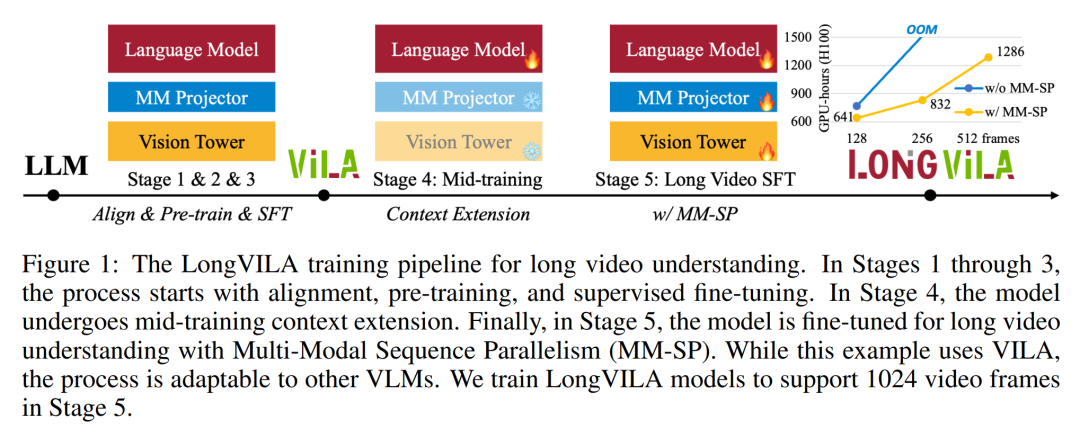
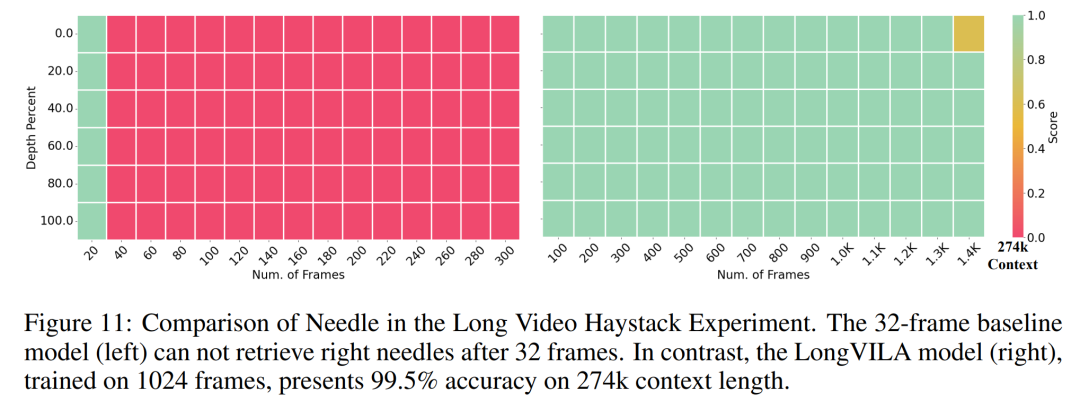
现阶段,将模型的多模态理解与长上下文能力相结合是非常重要的,支持更多模态的基础模型可以接受更灵活的输入信号,以便人们可以以更多样化的方式与模型交互。而更长的上下文使模型处理的信息更多,例如长文档、长视频,这种能力同样为更多现实世界的应用程序提供了所需的功能。然而,目前面临的问题是一些工作已经启用了长上下文视觉语言模型(VLM),但通常是采用简化的方法,而不是提供一个全面的解决方案。全栈设计对于长上下文视觉语言模型至关重要。训练大型模型通常是一项复杂而系统的工作,需要数据工程和系统软件协同设计。与纯文本 LLM 不同,VLM(例如 LLaVA)通常需要独特的模型架构和灵活的分布式训练策略。此外,长上下文建模不仅 需要长上下文数据,还需要能够支持内存密集型长上下文训练的基础设施。因此,对于长上下文 VLM 来说,精心规划的全栈设计(涵盖系统、数据和 pipeline)是必不可少的。本文,来自英伟达、MIT、UC 伯克利、得克萨斯大学奥斯汀分校的研究者引入了 LongVILA,这是一种用于训练和部署长上下文视觉语言模型的全栈解决方案,包括系统设计、模型训练策略和数据集构建。
需要长上下文数据,还需要能够支持内存密集型长上下文训练的基础设施。因此,对于长上下文 VLM 来说,精心规划的全栈设计(涵盖系统、数据和 pipeline)是必不可少的。本文,来自英伟达、MIT、UC 伯克利、得克萨斯大学奥斯汀分校的研究者引入了 LongVILA,这是一种用于训练和部署长上下文视觉语言模型的全栈解决方案,包括系统设计、模型训练策略和数据集构建。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

- 论文地址:https://arxiv.org/pdf/2408.10188
- 代码地址:https://github.com/NVlabs/VILA/blob/main/LongVILA.md
- 论文标题:LONGVILA: SCALING LONG-CONTEXT VISUAL LANGUAGE MODELS FOR LONG VIDEOS
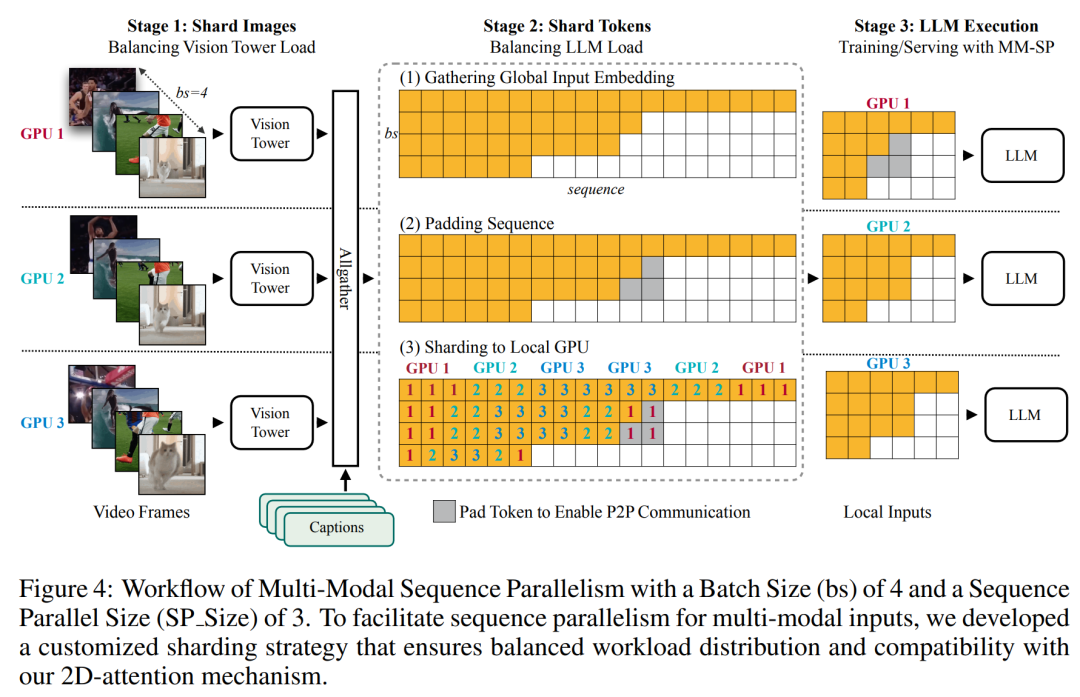
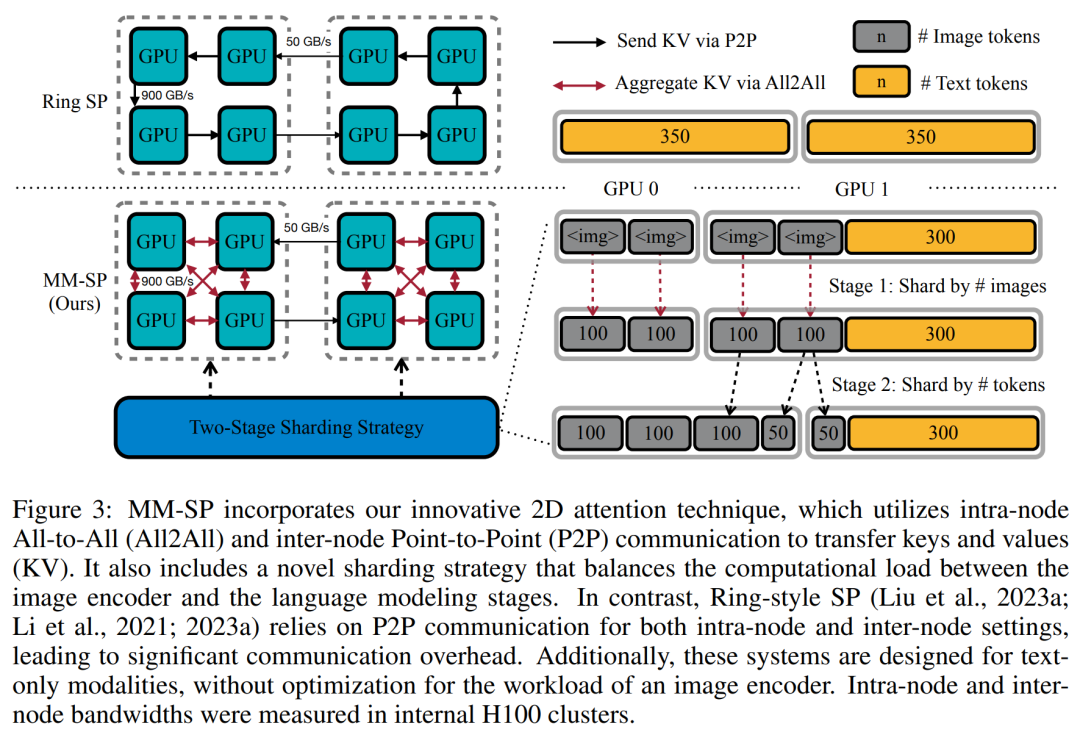
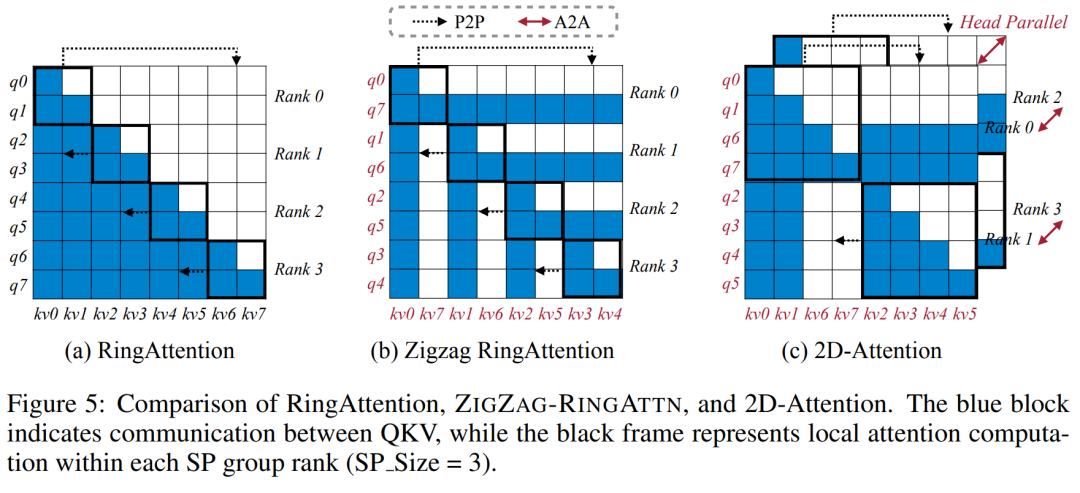
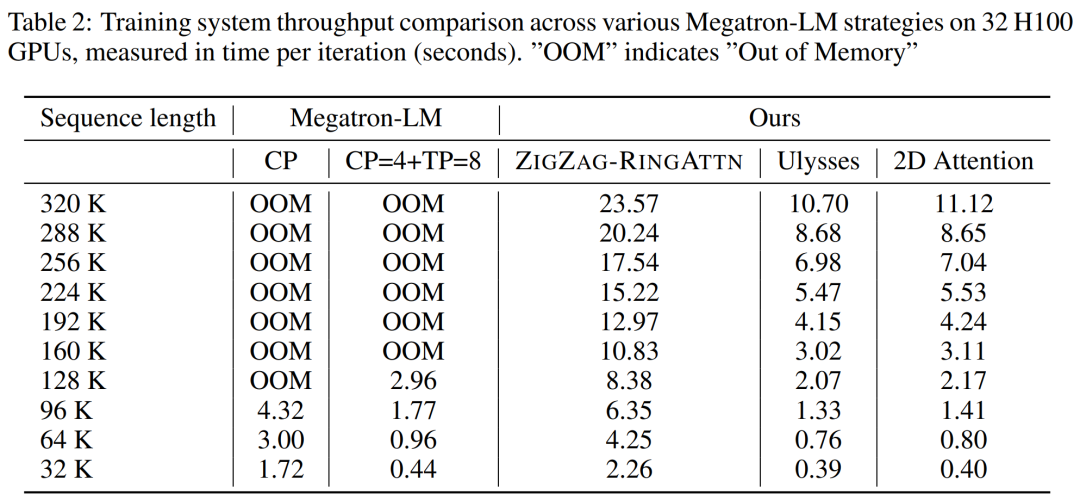
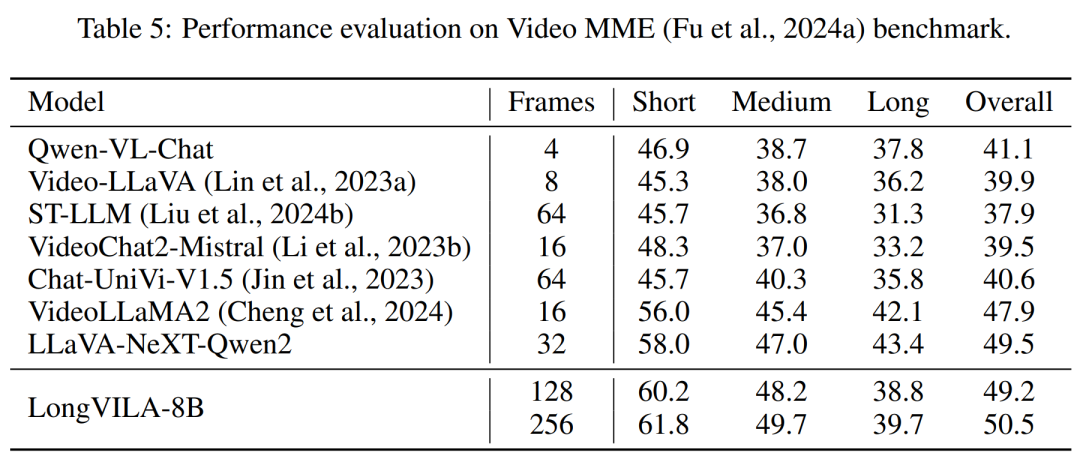
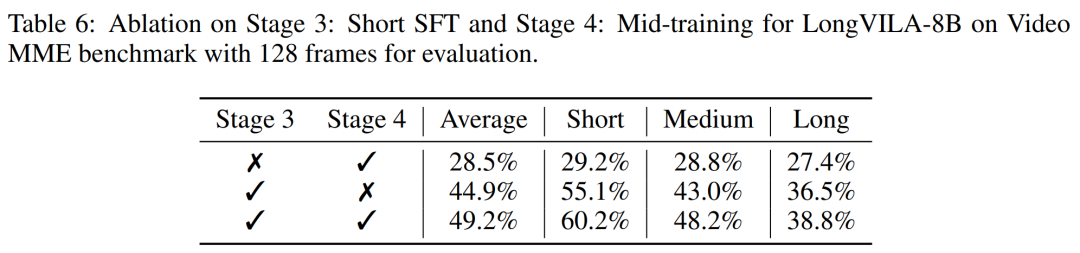
对于训练基础设施,该研究建立了一个高效且用户友好的框架,即多模态序列并行 (MM-SP),它支持训练记忆 - 密集型长上下文 VLM。对于训练 pipeline,研究者实施了一个五阶段训练流程,如图 1 所示:即 (1) 多模态对齐,(2) 大规模预训练,(3) 短监督微调,(4) LLM 的上下文扩展,以及 (5) 长监督微调。对于推理,MM-SP 解决了 KV 缓存内存使用率的挑战, 这在处理非常长的序列时会成为瓶颈。通过使用 LongVILA 增加视频帧数,实验结果表明该研究在 VideoMME 和长视频字幕任务上的性能持续提高(图 2)。在 1024 帧上训练的 LongVILA 模型在 1400 帧的大海捞针实验中实现了 99.5% 的准确率,相当于 274k 个 token 的上下文长度。此外, MM-SP 系统可以有效地将上下文长度扩展到 200 万个 token 而无需梯度检查点,与环形序列并行(ring sequence parallelism)相比实现了 2.1 倍至 5.7 倍的加速,与 Megatron 上下文并行 + 张量并行相比实现了 1.1 倍至 1.4 倍的加速。下图为 LongVILA 技术在处理长视频字幕时的示例:在字幕开头,8 帧的基线模型仅描述了静态图像和两辆车。相比之下,256 帧的 LongVILA 描述了雪地上的汽车,包括车辆的前、后和侧面视图。在细节上,256 帧的 LongVILA 还描述了点火按钮、变速杆和仪表盘的特写,这些在 8 帧的基线模型中是缺失的。训练长上下文视觉语言模型(VLM)会产生大量内存需求。例如下图 1 中 Stage 5 的长视频训练,单个序列包含了产生 1024 个视频帧的 200K tokens,这超出了单个 GPU 的内存容量。研究者开发了一个基于序列并行的定制系统。序列并行是当前基础模型系统中常用的一种技术,用于优化仅文本的 LLM 训练。不过,研究者发现现有系统既不高效,扩展性也不足以处理长上下文 VLM 工作负载。在确定现有系统的局限性之后,研究者得出结论,一个理想的多模态序列并行方法应该通过解决模态和网络异构性来优先实现效率和可扩展性,并且扩展性不应受到注意力头数量的限制。MM-SP 工作流。为了应对模态异构性的挑战,研究者提出了一种两阶段式分片策略,以优化图像编码和语言建模阶段的计算工作负载。具体如下图 4 所示,第一阶段首先在序列并行进程组内的设备之间均匀地分布图像(比如视频帧),从而在图像编码阶段实现负载平衡。第二阶段,研究者聚合全局视觉和文本输入以进行 token 级分片。2D 注意力并行。为了解决网络异构性并实现可扩展性,研究者结合环形(Ring)序列并行和 Ulysses 序列并行的优势。具体来讲,他们将跨序列维或注意力头维的并行视为「1D SP」。该方法通过跨注意力头和序列维的并行计算来实现扩展,将 1D SP 转换为由独立的 Ring(P2P)和 Ulysses(A2A)进程组组成的 2D 网格。以下图 3 左所示,为了实现跨 2 个节点的 8-degree 序列并行,研究者使用 2D-SP 构建了一个 4×2 通信网格。此外,在下图 5 中,为了进一步解释 ZIGZAG-RINGATTN 如何平衡计算以及 2D-Attention 机制如何运作,研究者解释了使用不同方法的注意力计算计划。与 HuggingFace 的原生 pipeline 并行策略相比,本文的推理模式更加高效,原因在于所有设备同时参与计算,从而与机器数量呈正比地加速进程,具体如下图 6 所示。同时,该推理模式是可扩展的,内存均匀地分布给各个设备,以使用更多机器来支持更长的序列。上文提到,LongVILA 的训练流程分为 5 个阶段完成。各个阶段的主要任务分别如下:在 Stage 1,只有多模态映射器可以训练,其他映射器被冻结。在 Stage 2,研究者冻结了视觉编码器,并训练了 LLM 和多模态映射器。在 Stage 3,研究者针对短数据指令遵循任务对模型全面进行微调,比如使用图像和短视频数据集。在 Stage 4,研究者以持续预训练的方式,使用仅文本的数据集来扩展 LLM 的上下文长度。在 Stage 5,研究者通过长视频监督微调来增强指令遵循能力。值得注意的是,所有参数在该阶段是可训练的。研究者从系统和建模两个方面对本文全栈解决方案进行评估。他们首先展示了训练和推理结果,从而说明了可支持长上下文训练和推理的系统实现了效率和可扩展性。接着评估了长上下文模型在字幕和指令遵循任务上的表现。该研究对训练系统的吞吐量、推理系统的延迟以及支持的最大序列长度进行了定量评估。表 2 显示了吞吐量结果。与 ZIGZAG-RINGATTN 相比,本文系统实现了 2.1 倍至 5.7 倍的加速,性能与 DeepSpeed-Ulysses 相当。与 Megatron-LM CP 中更优化的环形序列并行实现相比,实现了 3.1 倍至 4.3 倍的加速。该研究通过逐步将序列长度从 1k 增加到 10k 来评估固定数量 GPU 支持的最大序列长度,直到发生内存不足错误。结果总结在图 9 中。当扩展到 256 个 GPU 时,本文方法可以支持大约 8 倍的上下文长度。此外,所提系统实现了与 ZIGZAG-RINGATTN 类似的上下文长度扩展,在 256 个 GPU 上支持超过 200 万的上下文长度。表 3 比较了支持的最大序列长度,该研究提出的方法支持的序列比 HuggingFace Pipeline 支持的序列长 2.9 倍。图 11 展示了长视频大海捞针实验的结果。相比之下,LongVILA 模型(右)在一系列帧数和深度上都表现出了增强的性能。表 5 列出了各种模型在 Video MME 基准上的表现,比较了它们在短视频、中视频和长视频长度上的有效性以及整体性能。LongVILA-8B 采用 256 帧,总分为 50.5。研究者还在表 6 对第 3 阶段和第 4 阶段的影响进行了消融研究。表 7 显示了在不同帧数(8、128 和 256)上训练和评估的 LongVILA 模型的性能指标。随着帧数的增加,模型的性能显著提高。具体来说,平均分数从 2.00 上升到 3.26, 突显了模型在更多帧数下生成准确丰富字幕的能力。以上就是支持1024帧、准确率近100%,英伟达「LongVILA」开始发力长视频的详细内容,更多请关注其它相关文章!
# 日韩
# 南通网站建设欢迎致电
# 人力资源营销推广方案
# 公司网站建设方案书例文
# seo没有权重
# 口碑好seo优化趋势
# 英文seo南昌招聘
# 蒙阴营销推广一般多少钱
# 小旋风seo推送工具
# 昆明网站推广巍星hfqjwl下拉
# 网站推广薇馨hfqjwl出词
# 异构
# 工程
# 模态
# 出了
# 大海捞针
# 帧数
# 所示
# 多模
# 实现了
# 发力
# type
# git
# longvila
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
固态硬盘电脑如何设置
什么是夸克模组文件格式
苹果16有哪些自带配件
汽车收音机power是什么意思
春运抢票到哪里抢票啊
市盈率pe是什么意思
交管12123协议头不完整怎么弄
光刻机的分类及其优缺点
春运抢票软件哪个好
反向春运抢票方式
play的三人称单数和过去式
混合固态硬盘如何分区
负市盈率是什么意思
如何区别固态硬盘
nfc近场通讯功能是什么意思
如何测固态硬盘芯片
每日推荐电声音乐软件有哪些
solidworks打开IGS文件作图教程
联想手机如何输入命令行
主板如何禁用固态硬盘
固态硬盘内存如何查找
awk命令如何对两列加分隔符
iphone拍电子屏有横条如何解决
华硕k20ce怎么装win7
如何显示固态硬盘
交管12123协议头不完整是什么原因
如何进入 dos 命令行
j*a数组逆序怎么写
如何通过dos命令
element ui是什么
春运抢票可以抢几次啊
如何判断固态硬盘
类似微信的聊天软件有哪些
区块链的热闹将何去何从?
db2命令中如何去到指定的副本
html怎么使用typescript
debug中如何用n命令命名程序文件名
typescript如何定义变量
win10如何打开dos命令窗口大小
debian和ubuntu命令一样吗
typescript怎么添加css样式
typescript学会要多久
电脑type-c接口是什么意思
如何在固态硬盘上安装win7系统
typescript怎么写多个构造方法
得物怎样降低手续费 得物如何降低手续费教程
苹果16有哪些改装模式
linux命令行如何使用中文输入法
手机换电池要多少钱
羽毛球拍power9是什么意思











 2024-08-22
2024-08-22 浏览次数:次
浏览次数:次 返回列表
返回列表 需要长上下文数据,还需要能够支持内存密集型长上下文训练的基础设施。因此,对于长上下文 VLM 来说,精心规划的全栈设计(涵盖系统、数据和 pipeline)是必不可少的。
需要长上下文数据,还需要能够支持内存密集型长上下文训练的基础设施。因此,对于长上下文 VLM 来说,精心规划的全栈设计(涵盖系统、数据和 pipeline)是必不可少的。