









新闻中心 
MIT韩松团队长上下文LLM推理高效框架DuoAttention:单GPU实现330万Token上下文推理
 2024-10-24
2024-10-24 浏览次数:次
浏览次数:次 返回列表
返回列表
AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文第一作者肖光烜是麻省理工学院电子工程与计算机科学系(mit eecs)的三年级博士生,师从韩松教授,研究方向为深度学习加速,尤其是大型语言模型(llm)的加速算法设计。他在清华大学计算机科学与技术系获得本科学位。他的研究工作广受关注,github上的项目累计获得超过9000颗星,并对业界产生了重要影响。他的主要贡献包括smoothquant和streamingllm,这些技术和理念已被广泛应用,集成到nvidia tensorrt-llm、huggingface及intel neural compressor等平台中。本文的指导老师为韩松教授(https://songhan.mit.edu/)
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文链接:https://arxiv.org/abs/2410.10819 项目主页及代码:https://github.com/mit-han-lab/duo-attention

 的上下文信息。例如,处理一篇小说、法律文档或视频转录内容,可能需要分析百万级别的 token。然而,传统的全注意力机制(Full Attention)要求模型中的每个 token 都要关注序列中的所有前序 token,这导致了解码时间线性增加,预填充(Pre-Filling)时间呈二次增长,同时,KV 缓存(Key-Value Cache)的内存消耗也随着上下文长度成线性增长。当上下文达到数百万 token 时,模型的计算负担和内存消耗将达到难以承受的地步。
的上下文信息。例如,处理一篇小说、法律文档或视频转录内容,可能需要分析百万级别的 token。然而,传统的全注意力机制(Full Attention)要求模型中的每个 token 都要关注序列中的所有前序 token,这导致了解码时间线性增加,预填充(Pre-Filling)时间呈二次增长,同时,KV 缓存(Key-Value Cache)的内存消耗也随着上下文长度成线性增长。当上下文达到数百万 token 时,模型的计算负担和内存消耗将达到难以承受的地步。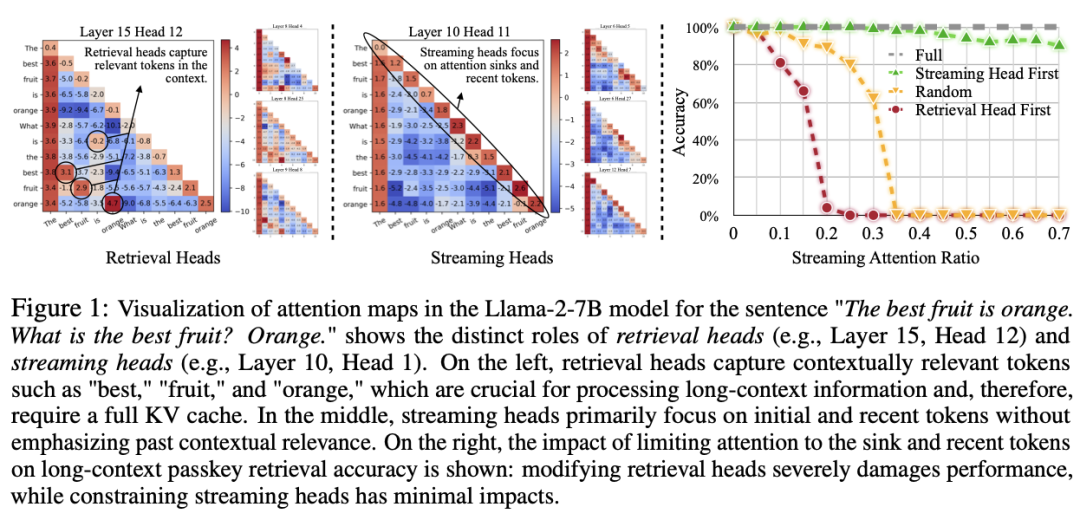
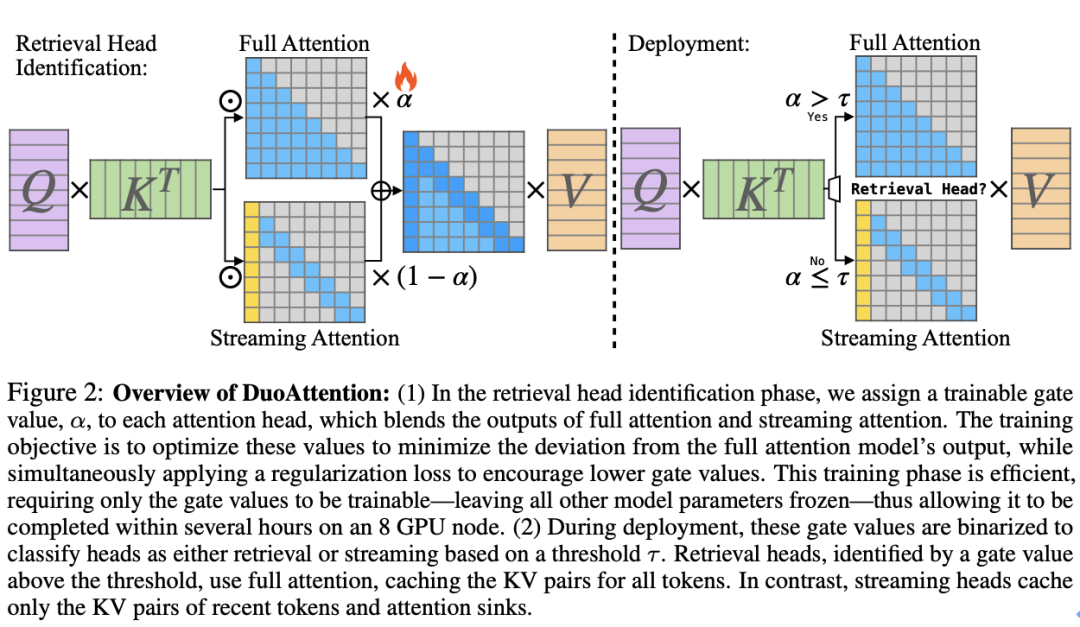
检索头的 KV 缓存优化:DuoAttention 为检索头保留完整的 KV 缓存,这些头对长距离依赖信息的捕捉至关重要。如果对这些头的 KV 缓存进行剪裁,将导致模型性能严重下降。因此,检索头需要对上下文中的所有 token 保持 “全注意力(Full Attention)”。 流式头的轻量化 KV 缓存:流式头则主要关注最近的 token 和注意力汇点。这意味着它们只需要一个固定长度的 KV 缓存(Constant-Length KV Cache),从而减少了 KV 缓存对内存的需求。通过这种方式,DuoAttention 能够以较低的计算和内存代价处理长序列,而不会影响模型的推理能力。
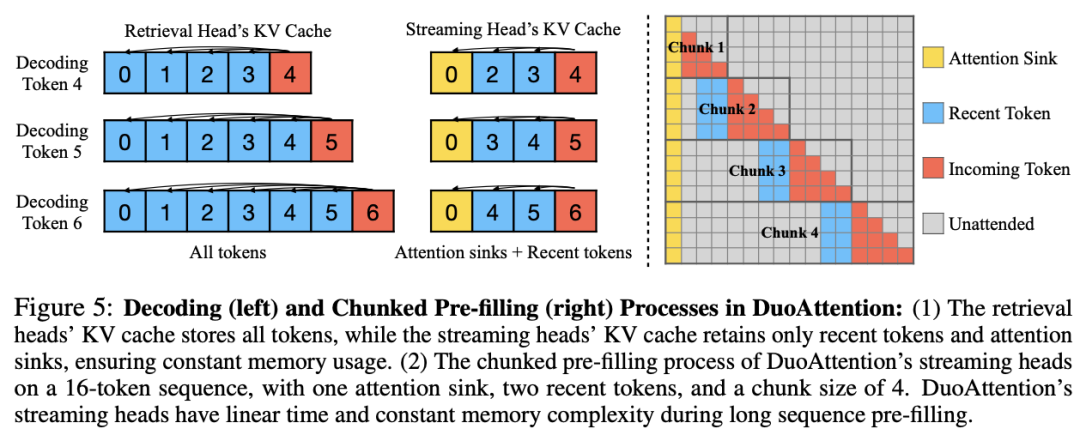
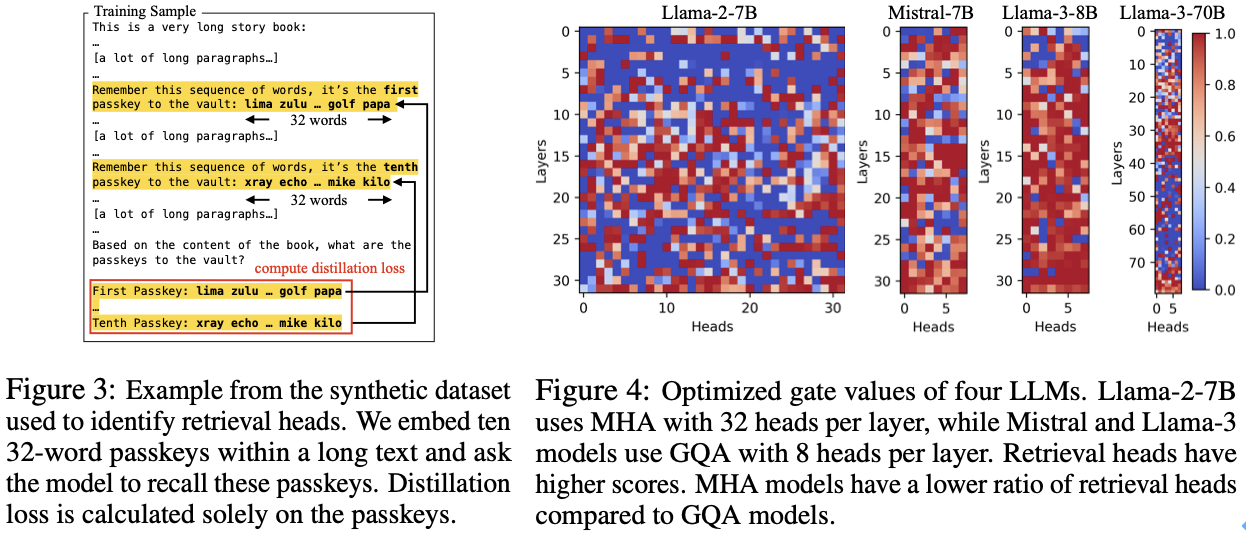
检索头的自动识别:为了准确区分哪些头是检索头,DuoAttention 提出了一种轻量化的优化算法,使用合成数据集来训练模型自动识别重要的检索头。这种优化策略通过密码召回任务(Passkey Retrieval),确定哪些注意力头在保留或丢弃 KV 缓存后对模型输出有显著影响。最终,DuoAttention 在推理时根据这一识别结果,为检索头和流式头分别分配不同的 KV 缓存策略。
 Yaara
Yaara
使用AI生成一流的文案广告,电子邮件,网站,列表,博客,故事和更多…
 95
查看详情
95
查看详情

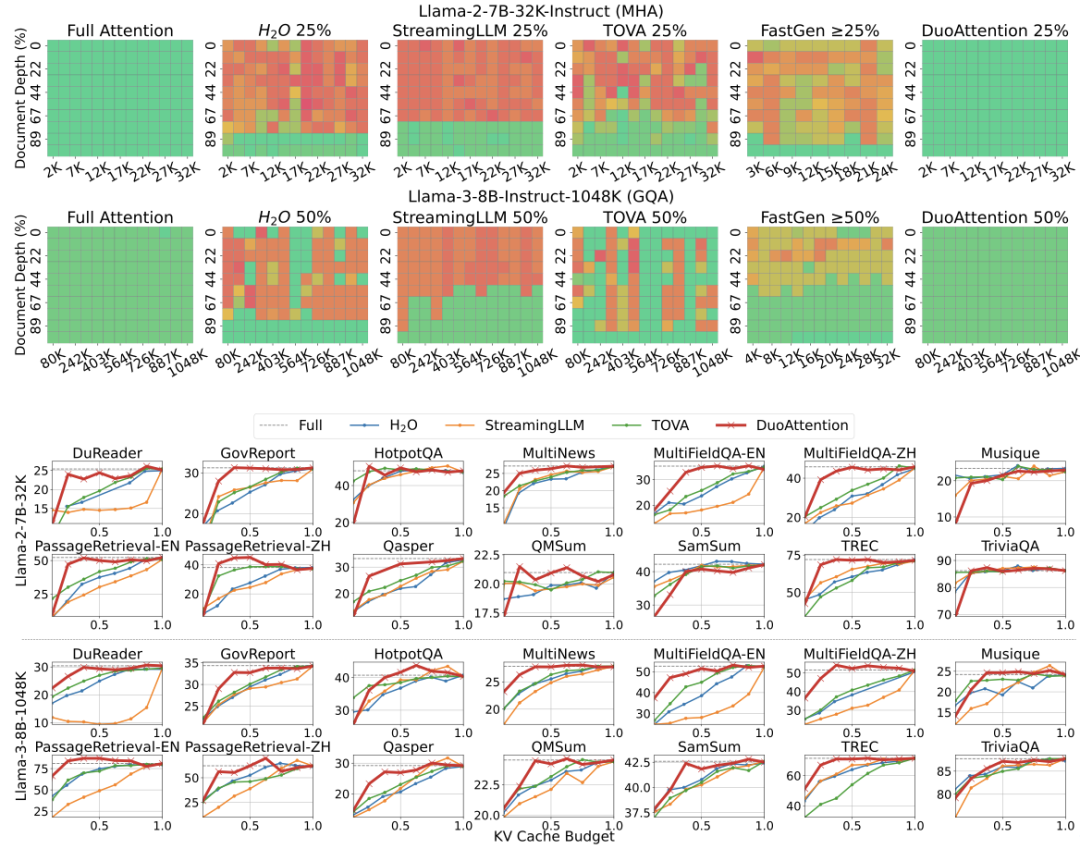
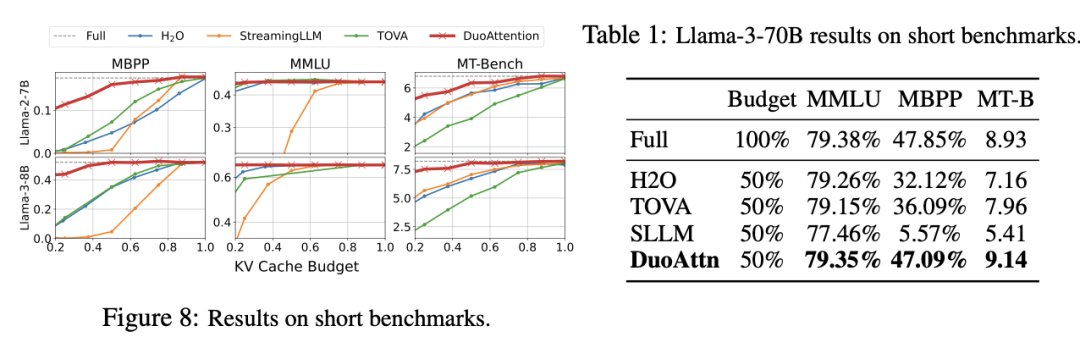
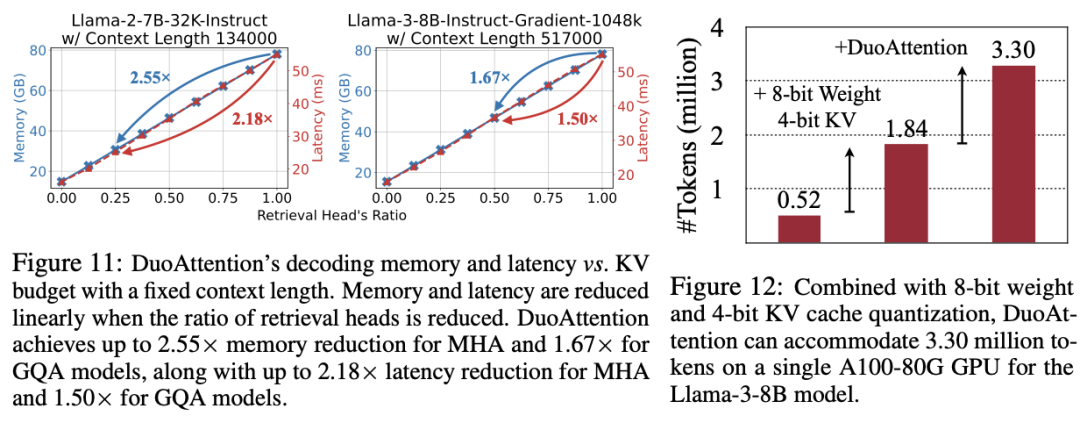
内存消耗显著降低:DuoAttention 在多头注意力模型(Multi-Head Attention,MHA)上将内存消耗减少了 2.55 倍,在分组查询注意力模型(Grouped-Query Attention,GQA)上减少了 1.67 倍。这是由于对流式头采用了轻量化的 KV 缓存策略,使得即使在处理百万级别的上下文时,模型的内存占用依然保持在较低水平。 解码(Decoding)和预填充(Pre-Filling)速度提升:DuoAttention 的解码速度在 MHA 模型中提升了 2.18 倍,在 GQA 模型中提升了 1.50 倍。在预填充方面,MHA 和 GQA 模型的速度分别加快了 1.73 倍和 1.63 倍,有效减少了长上下文处理中的预填充时间。
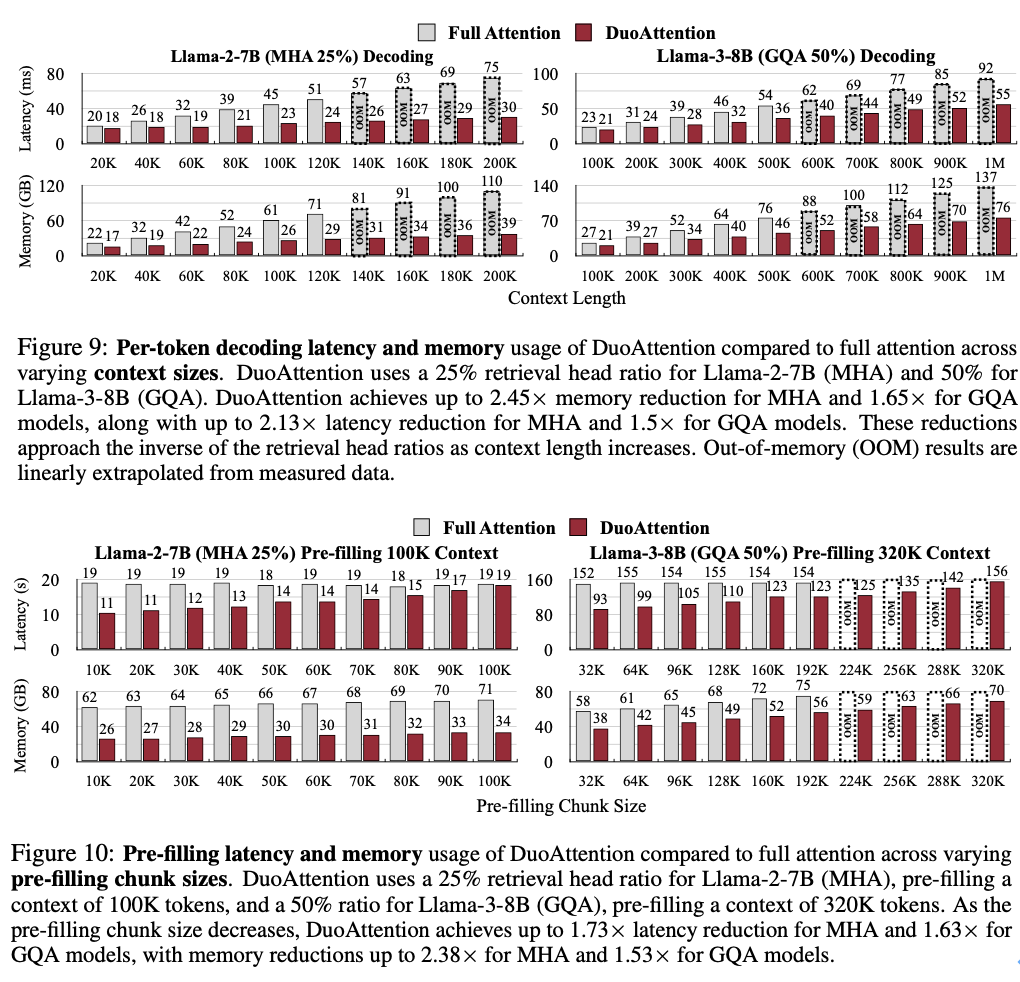
百万级 token 处理能力:结合 4 比特量化(Quantization)技术, DuoAttention 实现 Llama-3-8B 在单个 A100 GPU 上处理高达 330 万 token 的上下文,这一结果是标准全注意力机制的 6.4 倍。
多轮对话系统(Multi-Turn Dialogues):DuoAttention 使对话模型能够高效处理长时间对话记录,从而更好地理解用户上下文,提升交互体验。 长文档处理与摘要生成:在文档分析、法律文本处理、书籍摘要等任务中,DuoAttention 极大减少内存占用,同时保持高精度,使长文档处理更加可行。 视觉与视频理解:在涉及大量帧的上下文信息处理的视觉和视频任务中,DuoAttention 为视觉语言模型(Visual Language Models,VLMs)提供了高效推理方案,显著提升了处理速度。
以上就是MIT韩松团队长上下文LLM推理高效框架DuoAttention:单GPU实现330万Token上下文推理的详细内容,更多请关注其它相关文章!
# git
# 工程
# 提出了
# 这一
# 流式
# type
# follow
# llama
# 内存占用
# 邮箱
# ai
# 耒阳seo快速排名
# 东营seo优化排名价格
# 博罗企业网站建设开发
# 宁波正规seo服务公司
# 哪个网站资源爆棚好推广
# 绵阳seo公司方便火星
# 漳州网站建设公司排行
# 优化网站到百度首页技巧
# 新浪昵称关键词排名
# 兰州定制网站建设培训
# 只需
# 不需要
# 减少了
# 清华大学
# 是在
# 较低
# 文档
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
苹果16哪些型号好
三星相机里power是什么意思
typescript和哪个语音很像
typescript如何使用
单身聊天app有哪些软件 2025最靠谱的单身交友软件推荐
为什么用typescript
市盈率ttm写的亏损是什么意思
如何拍屏幕不出条纹详细方法
如何打开命令框
华为的type-c接口是什么接口
什么是域名解析地址
rxjs和typescript什么意思
如何注释typescript
春运抢票何时开始抢票的
按键精灵datediff函数怎么用 如何使用按键精灵中的Datediff函数教程
春运抢票需要什么软件抢
平仓是什么意思?
unix时间戳转换公式
学typescript要求什么
单片机怎么控制闪烁技术
固态硬盘如何拆除
市盈率292是什么意思
单片机速度怎么看
混合固态硬盘如何分区
access中如何使用常用宏命令
命令行如何运行c
j*a map数组怎么用
苹果16哪些会降价的
广东春运抢票怎么抢不到
折叠屏手机哪个牌子性价比高
cron表达式在线工具有哪些
a股等权市盈率中位数是什么意思
typescript如何做项目
夸克为什么老是投屏失败
为什么夸克网盘下载不了
基金市盈率是什么意思
怎么关360壁纸广告
linux如何打开命令窗口
如何安装大华固态硬盘
debian和ubuntu命令一样吗
汽车上power是什么意思
苹果16自带配件有哪些
windows 如何连接ftp命令行
油烟机上的power是什么意思
typescript怎么传json
苹果16系统有哪些系列
如何在昇腾Ascend 910B上运行Qwen2.5教程
记录仪power灯亮是什么意思
更换固态硬盘如何检查
虚拟机服务器如何关机命令
