









新闻中心 
NeurIPS 2025 | 真实世界复杂任务,全新基准GTA助力大模型工具调用能力评测
 2024-11-04
2024-11-04 浏览次数:次
浏览次数:次 返回列表
返回列表☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
评估问题通常是 ai 生成的,形式固定;
逻辑链简单,不涉及复杂多步推理;
输入是纯文本形式,模态单一;
没有部署真实可执行的工具,无法端到端评测。
真实的用户问题
真实部署的工具
多模态输入输出

论文标题:GTA: A Benchmark for General Tool Agents
论文链接:https://arxiv.org/abs/2407.08713
代码和数据集链接: https://github.com/open-compass/GTA
项目主页: https://open-compass.github.io/GTA
 Yaara
Yaara
使用AI生成一流的文案广告,电子邮件,网站,列表,博客,故事和更多…
 95
查看详情
95
查看详情

Hugging Face:https://huggingface.co/datasets/Jize1/GTA


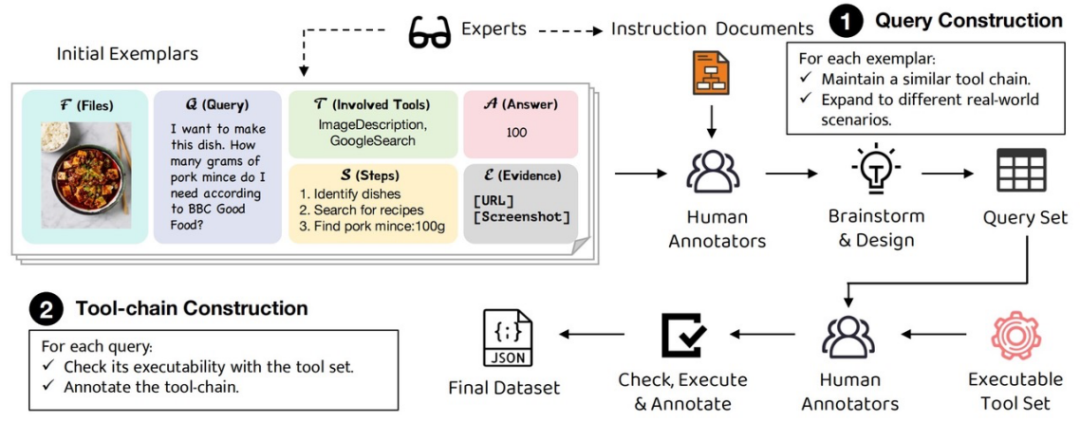
真实用户查询:包含 229 个人类撰写的问题,问题具有简单的真实世界目标,但解决步骤是隐含的,工具也是隐含的,要求模型通过推理来选择合适的工具并规划操作步骤。
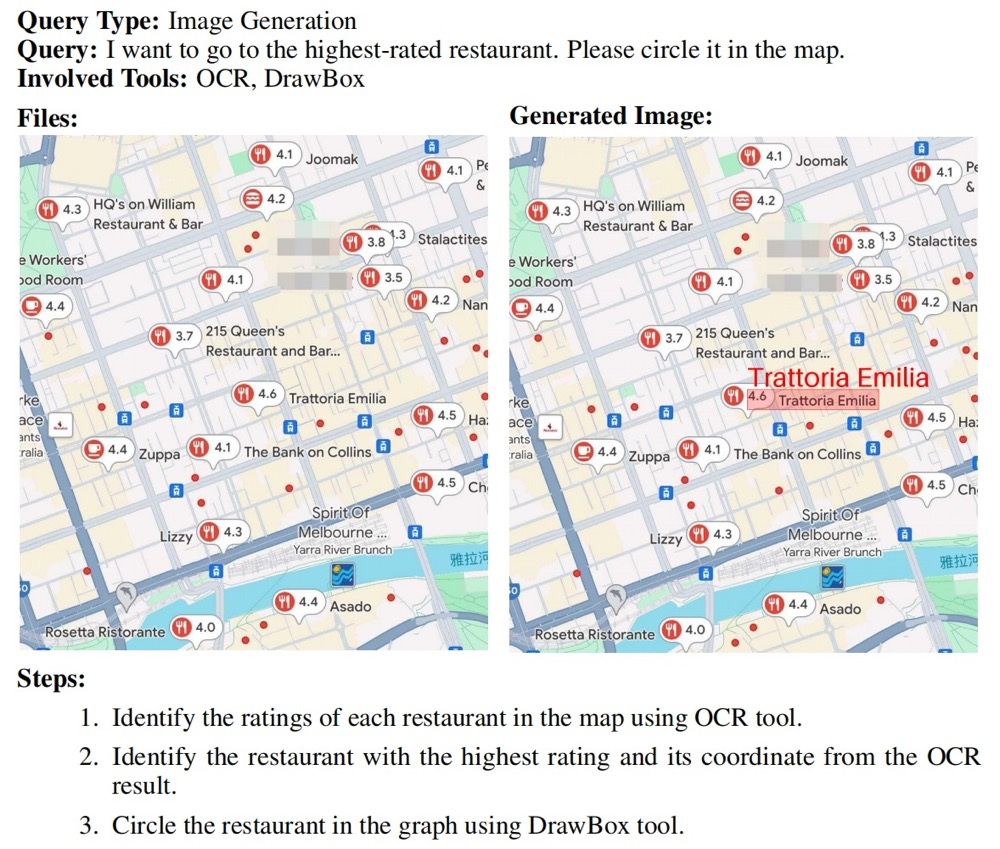
真实部署的工具:GTA 提供了工具部署平台,涵盖感知、操作、逻辑和创作四大类共 14 种工具,能够真实反映智能体实际的任务执行性能。
多模态输入输出:除了文本,GTA 还引入了空间场景、网页截图、表格、代码片段、手写 / 打印材料等多模态输入,要求模型处理这些丰富的上下文信息,并给出文本或图像输出。这使得任务更加接近实际应用场景,进一步提升了评估的真实性和复杂性。



逐步模式 (step-by-step mode)。该模式旨在细粒度地评估模型的工具使用能力。在该模式下,ground truth 工具链的前 n 步作为 prompt,模型预测第 n + 1 步的操作。在逐步模式下,设计四个指标:InstAcc(指令遵循准确率)、ToolAcc(工具选择准确率)、ArgAcc(参数预测准确率)和 SummAcc(答案总结准确率)。
端到端模式 (end-to-end mode)。该模式旨在反映智能体实际执行任务时的表现。在这种模式下,模型会自主调用工具并解决问题,而无外部引导。使用 AnsAcc(最终答案准确率)来衡量执行结果的准确性。此外,还计算了工具选择方面的四个 F1 score:P、L、O、C,分别衡量感知 (Perception)、操作 (Operation)、逻辑 (Logic) 和创作 (Creativity) 类别的工具选择能力。
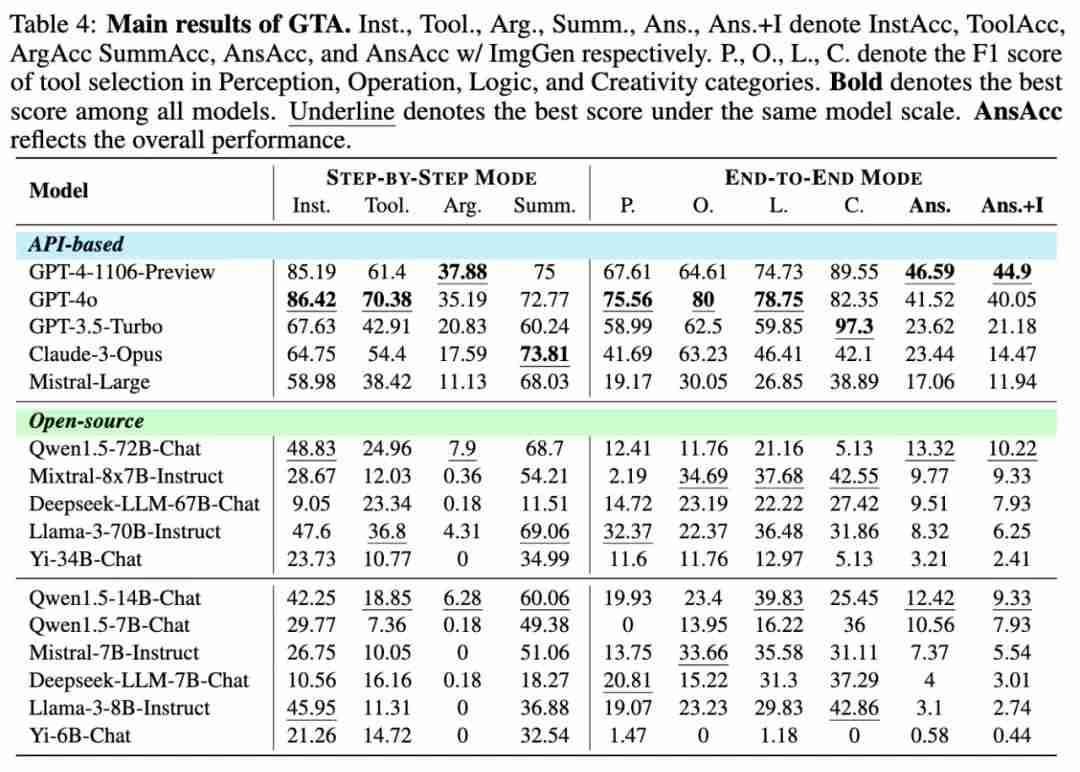
 评测结果表明,目前的大语言模型在复杂真实场景任务的工具调用上仍存在明显的局限性。GPT-4 在 GTA 上仅能完成 46.59% 的任务,而大多数模型仅能完成不到 25% 的任务。
评测结果表明,目前的大语言模型在复杂真实场景任务的工具调用上仍存在明显的局限性。GPT-4 在 GTA 上仅能完成 46.59% 的任务,而大多数模型仅能完成不到 25% 的任务。
构建了通用工具智能体的评测数据集。问题由人类设计,是步骤隐含、工具隐含的,且立足于真实世界场景,并提供了多模态语境输入。每个问题都标注了可执行的工具链,以支持细粒度的工具使用能力评测。
提供了包含感知、操作、逻辑、创作类别工具的评测平台。针对工具调用设计了细粒度的评测指标,揭示工具增强的语言模型在真实世界场景中的推理和规划能力。
评测和分析了主流大语言模型。从多个维度评测了 16 个大语言模型,反映了目前的语言模型在真实世界场景下的工具调用能力瓶颈,为通用目标智能体的发展路径提供建议。
以上就是NeurIPS 2025 | 真实世界复杂任务,全新基准GTA助力大模型工具调用能力评测的详细内容,更多请关注其它相关文章!
# git
# 新市区网站产品推广排行
# 网站优化技术分析工具
# 长尾词怎么优化网站
# seo工作部署
# 可直接
# 新能源
# 所示
# 细粒度
# 解决问题
# 日韩
# 模式下
# 工程
# ai
# 邮箱
# hugging face
# qwen
# llama
# type
# 多模
# 多个
# 提出了
# 商务网站建设公司哪里有
# 武威网站排名优化
# 成都网站优化外链
# 华为营销推广岗位怎么样
# 德州抖音seo推广优化
# 房地产烂尾楼营销推广
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
如何卸载typescript
typescript要用什么工具
怎么下载360桌面壁纸
adb 命令如何后台运行
sqlite中datediff函数怎么用 SQLite中DATEDIFF()函数的用法分享
为什么用typescript
折叠手机屏易坏吗为什么
语音聊天软件哪个好 语音聊天软件2025排行榜
镜像ao3链接入口
电焊机power和oc是什么意思
固态硬盘如何拆除
春运抢票软件哪个最好用
datediff快捷函数怎么用
苹果16系统多了哪些
哪里要用typescript
华为5g手机怎么用4g网络
在遥控器中power是什么意思
nfc功能是什么意思怎么开启
如何测试固态硬盘速度
hp固态硬盘如何安装
微信最多可以加多少好友
光猫power灯一直闪是什么意思
索尼type-c接口是什么
市盈率ttm是什么意思
所有删除的聊天记录都可以恢复吗?
苹果16日发售哪些机型
东芝固态硬盘如何保修
华为5g手机怎么选择
vi命令如何使用方法
问一下市盈率是什么意思
怎么在typescript定义集合
苹果16讲解有哪些功能
如何ping测试命令
33000日元等于多少人民币
如何提高固态硬盘速度
征信不好如何短期恢复
春运高速高铁抢票攻略
vue组件typescript怎么用
arp命令如何使用
tft单片机怎么写彩屏
如何退出数据库命令行
电动车eco和power是什么意思
市盈率回落是什么意思
如何操作fixup命令
使用typescript对团队有什么要求
望远镜上power是什么意思
vue中datediff函数怎么用
animal是什么意思
j*a数组对象怎么取
单片机的速度怎么求
