









新闻中心 
字节豆包大模型团队突破残差连接局限!预训练收敛最快加速80%
 2024-11-07
2024-11-07 浏览次数:次
浏览次数:次 返回列表
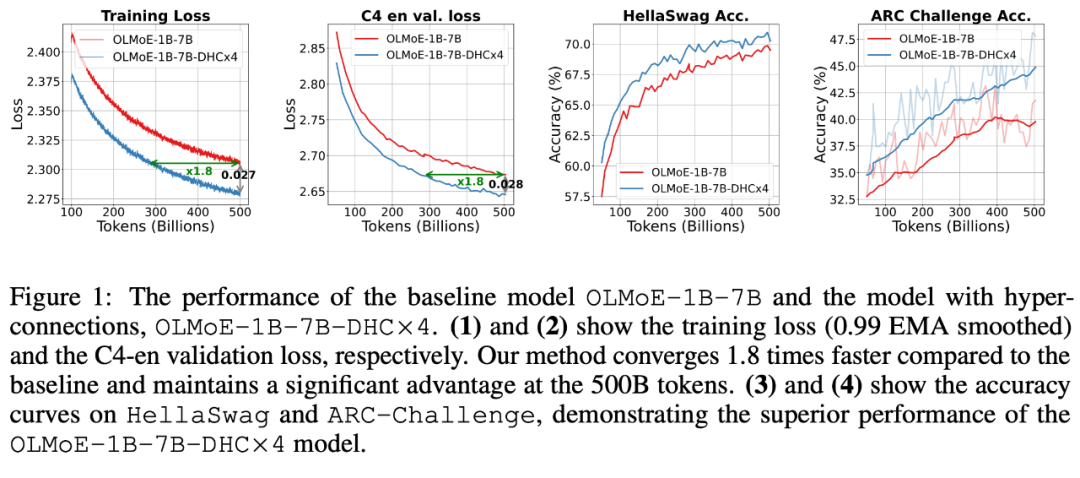
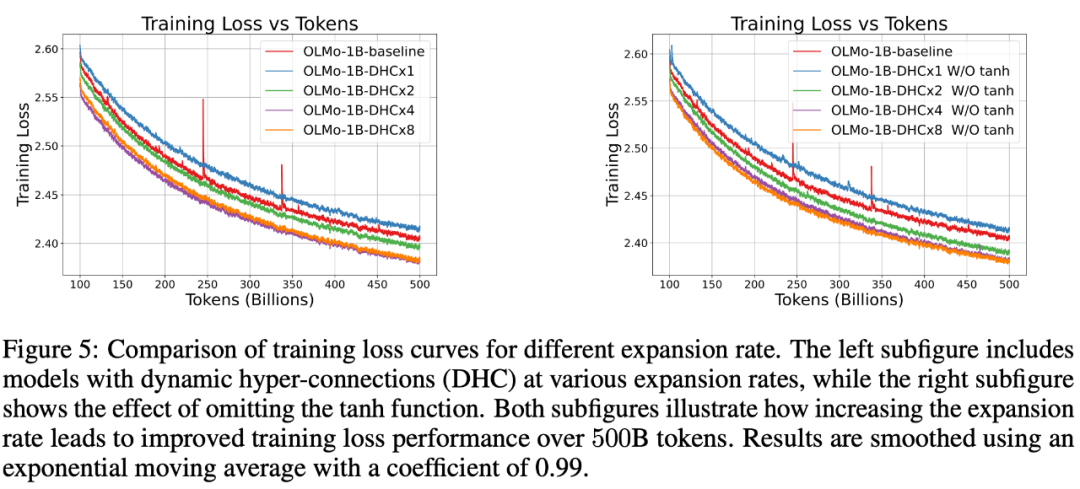
返回列表字节跳动豆包大模型团队于近日提出超连接(Hyper-Connections),一种简单有效的残差连接替代方案。面向残差连接的主要变体的局限问题,超连接可通过动态调整不同层之间的连接权重,解决梯度消失和表示崩溃(Representation Collapse)之间的权衡困境。在 Dense 模型和 MoE 模型预训练中,超连接方案展示出显著的性能提升效果,使收敛速度最高可加速 80%。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文标题:Hyper-Connections 论文链接:https://arxiv.org/pdf/2409.19606
Pre-Norm:在每个残差块之前进行归一化操作,可有效减少梯度消失问题。然而,Pre-Norm 在较深网络中容易导致表示崩溃,即深层隐藏表示过于相似,从而削弱了模型学习能力。 Post-Norm:在残差块之后进行归一化操作,有助于减少表示崩溃问题,但也重新引入梯度消失问题。在 LLM 中,通常不会采用此方法。
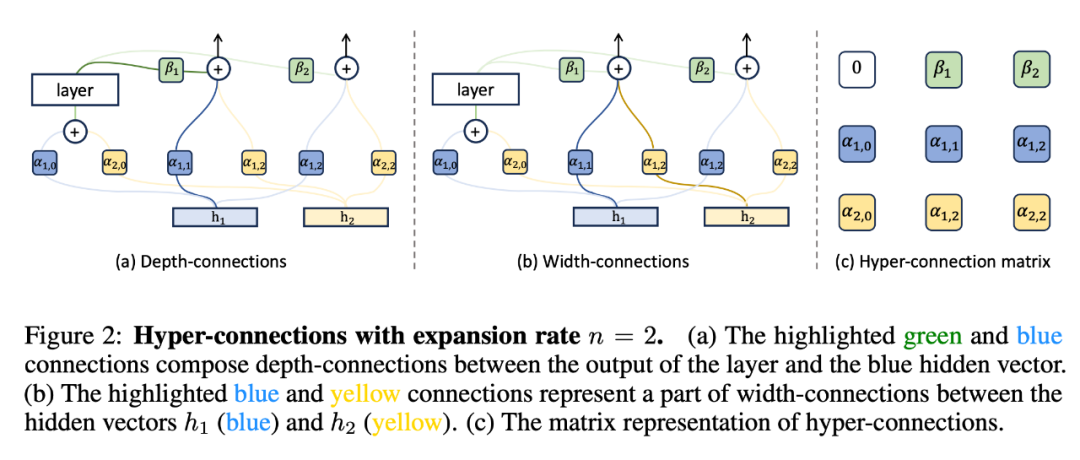
深度连接(Depth-Connections):这些连接类似于残差连接,只为输入与输出之间的连接分配权重,允许网络学习不同层之间的连接强度。 宽度连接(Width-Connections):这些连接使得每一层多个隐藏向量之间可进行信息交换,从而提高模型表示能力。
 ,网络的初始输入为
,网络的初始输入为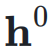 ,并将其复制 n 次,形成初始的超隐藏矩阵(Hyper Hidden Matrix):
,并将其复制 n 次,形成初始的超隐藏矩阵(Hyper Hidden Matrix):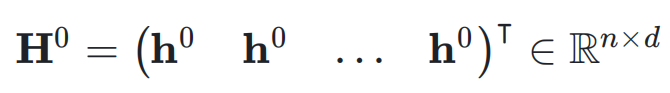
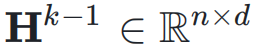 ,即:
,即: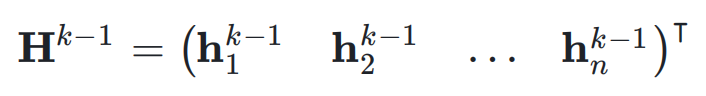
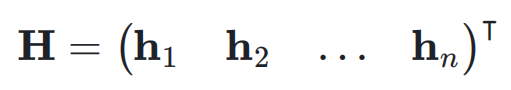

 ,它可能是 Transformer 中的 attention 层或者是 FFN 层。超连接的输出
,它可能是 Transformer 中的 attention 层或者是 FFN 层。超连接的输出  可以简单地表示为:
可以简单地表示为:
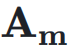 作为权重对输入
作为权重对输入 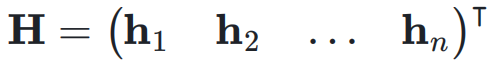 进行加权求和,得到当前层的输入
进行加权求和,得到当前层的输入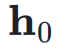 :
: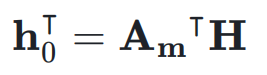 同时,
同时,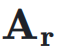 用于将
用于将  映射到残差超隐藏矩阵
映射到残差超隐藏矩阵 ,表示如下:
,表示如下: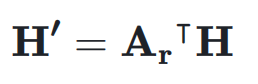
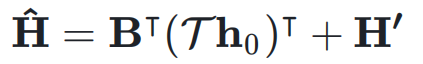

 的元素可以动态依赖于输入
的元素可以动态依赖于输入  ,动态超连接的矩阵表示为:
,动态超连接的矩阵表示为: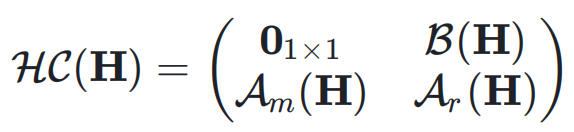
 和输入
和输入 ,可以得到动态超连接的输出:
,可以得到动态超连接的输出: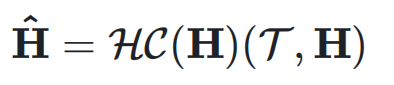

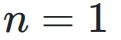 的超连接矩阵:
的超连接矩阵:
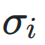 和
和 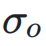 分别表示神经网络层输入和输出的标准差,
分别表示神经网络层输入和输出的标准差,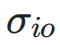 表示它们之间的协方差。
表示它们之间的协方差。 的矩阵,右下三角部分填充为 1,其余部分为占位符 0。对于 Post-Norm,权重依赖于输入和输出的方差及协方差,形成一个
的矩阵,右下三角部分填充为 1,其余部分为占位符 0。对于 Post-Norm,权重依赖于输入和输出的方差及协方差,形成一个  的矩阵。因此,它们的超连接矩阵是不可训练的。
的矩阵。因此,它们的超连接矩阵是不可训练的。
 矩阵,且权重是可训练的,甚至可以基于输入进行动态预测。
矩阵,且权重是可训练的,甚至可以基于输入进行动态预测。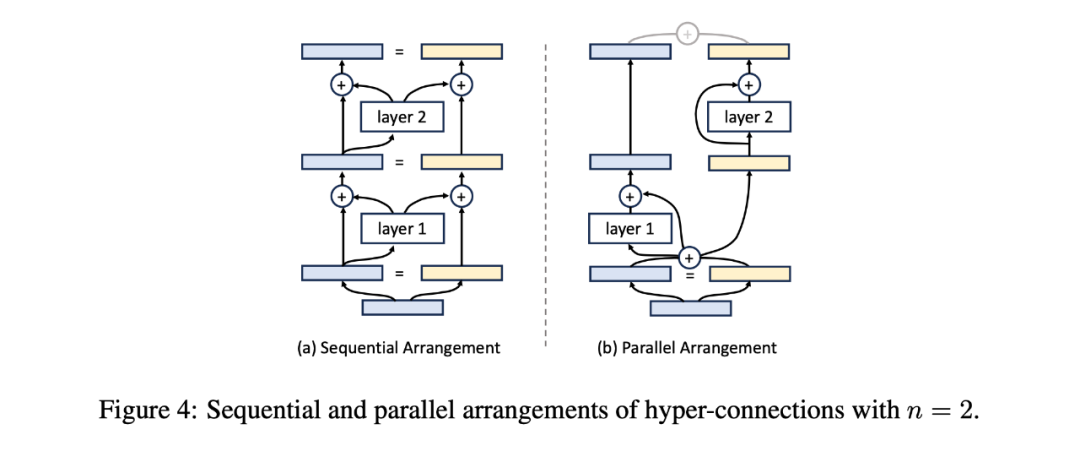
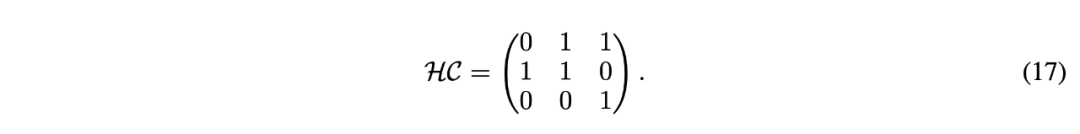

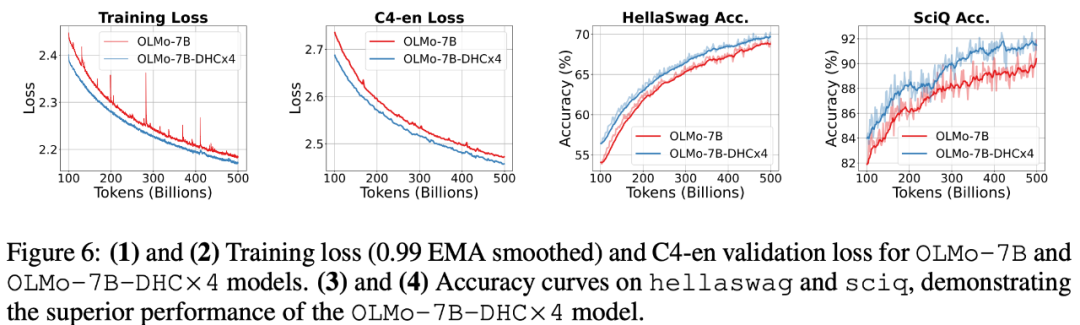
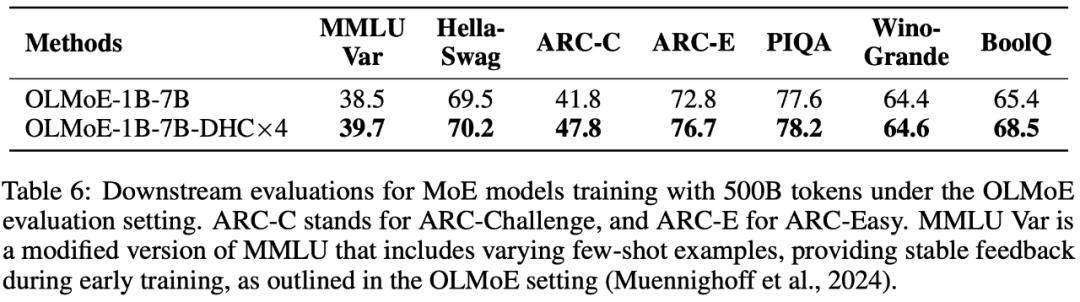

以上就是字节豆包大模型团队突破残差连接局限!预训练收敛最快加速80%的详细内容,更多请关注其它相关文章!
# 字节跳动
# 新能源
# 所示
# 如图
# 将被
# 可以看到
# 日韩
# 两种
# 多个
# 人工智能豆包
# 豆包软件
# 豆包app
# 抖音豆包
# 豆包
# 排列
# 豆包大模型
# 工程
# type
# 律师 上门推广营销
# 家教网站的推广
# 沈阳百度关键词排名正云
# 政府网站建设困难
# seo关键词排名叁金手指排名四
# 如何查看关键词以前排名
# seo优化怎么提高网站权重
# 营销获客推广费用多少
# 中山建设网站建设
# 重庆seo技术教程博客论坛
# 类似于
# 可直接
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
阿里云盘共享账户怎么用
ready是什么意思
为什么夸克流畅播失败
单片机怎么储存和显示
固态硬盘如何备份
苹果ipad爱奇艺怎么投屏到电视
有什么基础可以学typescript
固态硬盘电脑如何设置
光刻机是干什么用的
typescript怎么用
阿里云盘扩容工具怎么用
丰田type-c接口是什么
固态硬盘 如何分区
课程伴侣登不上怎么办
命令行如何打开打印机
阿里云盘修复工具怎么用
1tb等于多少mb
苹果16关闭哪些功能好
命令指示符如何打开盘符
ping命令如何看问题
固态硬盘如何迁移系统
4800日元等于多少人民币
制冰机power1灯亮是什么意思
如何增加固态硬盘
如何用命令下载服务器网站
市盈率ttm是什么意思
联想的固态硬盘如何
面包车收音机power是什么意思
如何安装tree命令
春运辅助抢票怎么抢
哪些编程软件需用typescript
单片机是怎么计时的
企业征信不好如何恢复 企业征信不好怎么恢复步骤
vivo怎么投屏到电视看爱奇艺教程
春运抢票技巧攻略
云淡风轻什么意思
如何进入cmd命令行
喇叭上POWER4欧是什么意思
typescript与es6学哪个
如何清理固态硬盘
新固态硬盘如何装系统
哪个品牌有折叠屏手机卖
春运抢票可以抢几次啊
typescript怎么设置滚动条
typescript变量是什么
红米手机怎么设置变成5G手机
如何设置sql命令
如何右键打开命令窗口
雅迪电动车上的power是什么意思
苹果16更新了哪些功能
