









新闻中心 
神级项目训练GPT-2仅需5分钟,Andrej Karpathy都点赞
 2024-11-21
2024-11-21 浏览次数:次
浏览次数:次 返回列表
返回列表租用 H100 的钱只需 233 美元。
 2 训练的项目「llm.c」曾经引发机器学习社区的热烈讨论。
2 训练的项目「llm.c」曾经引发机器学习社区的热烈讨论。☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

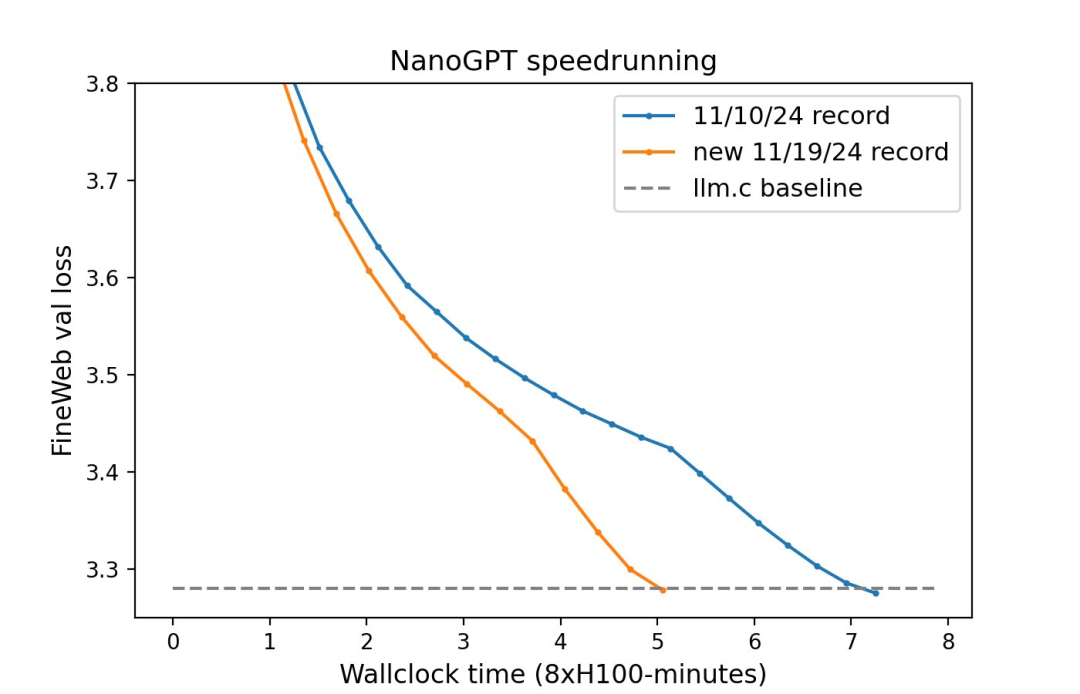
10B tokens-->1B tokens 8xH100 上花 45 分钟训练 -->8xH100 上花 5 分钟训练
先进的架构:旋转嵌入、QK-Norm 和 ReLU^2; 新优化器:Muon; 嵌入中的 Untied Head; 投影和分类层初始化为零(muP-like); 架构 shortcut:值残差和嵌入 shortcut(部分遵循论文《Value Residual Learning For Alleviating Attention Concentration In Transformers》); 动量(Momentum)warmup; Tanh soft logit capping(遵循 Gemma 2); FlexAttention。
<section><code>pip install -r requirements.txt</code></section><section><code>pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu124 —upgrade # install torch 2.6.0</code></section><section><code>python data/cached_fineweb10B.py 10 # downloads only the first 1.0B training tokens to s*e time</code></section><section><code>./run.sh</code></section>
<section><code>sudo apt-get update</code></section><section><code>sudo apt-get install vim tmux python3-pip python-is-python3 -y</code></section><section><code>git clone <a href="https://www.php.cn/link/e8cb5f581442030021d62fd780fa674d" rel="nofollow" target="_blank" >https://www.php.cn/link/e8cb5f581442030021d62fd780fa674d</a></code></section><section><code>cd modded-nanogpt</code></section><section><code>tmux</code><code></code><code></code><code>pip install numpy==1.23.5 huggingface-hub tqdm</code></section><section><code>pip install --upgrade torch &</code></section><section><code>python data/cached_fineweb10B.py 18</code></section>
<section><code>sudo docker build -t modded-nanogpt .</code></section><section><code>sudo docker run -it --rm --gpus all -v $(pwd):/modded-nanogpt modded-nanogpt python data/cached_fineweb10B.py 18</code></section><section><code>sudo docker run -it --rm --gpus all -v $(pwd):/modded-nanogpt modded-nanogpt sh run.sh</code></section>

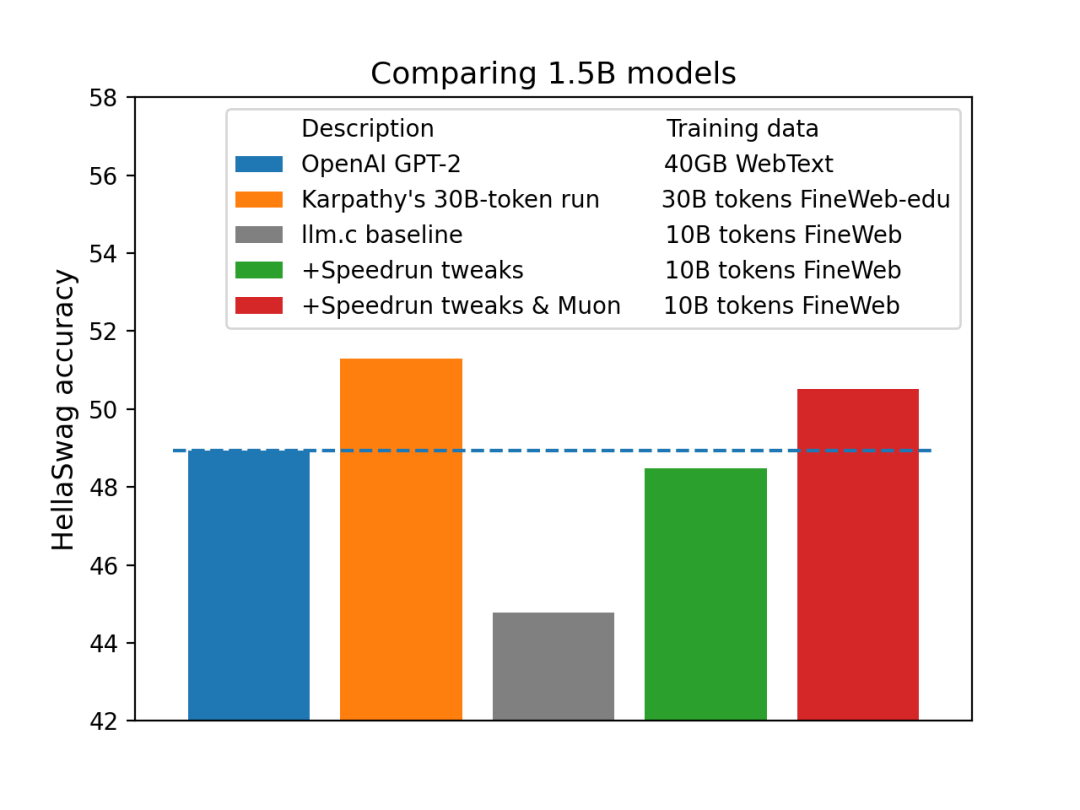

<section><code>@torch.compile</code></section><section><code>def zeroth_power_via_newtonschulz5 (G, steps=5, eps=1e-7):</code></section><section><code>assert len (G.shape) == 2</code></section><section><code>a, b, c = (3.4445, -4.7750,2.0315)</code></section><section><code>X = G.bfloat16 () / (G.norm () + eps)</code></section><section><code>if G.size (0) > G.size (1):</code></section><section><code>X = X.T</code></section><section><code> </code><code>for _ in range (steps):</code></section><section><code>A = X @ X.T</code></section><section><code>B = b * A + c * A @ A</code></section><section><code>X = a * X + B @ X</code></section><section><code>if G.size (0) > G.size (1):</code></section><section><code>X = X.T</code></section><section><code> </code><code> return X.to (G.dtype)</code></section>
内存使用量比 Adam 低 采样效率提高约 1.5 倍 挂钟开销小于 2%
在更新中使用 Nesterov 动量,在动量之后应用正交化。 使用特定的五次 Newton-Schulz 迭代作为正交化方法。 使用五次多项式的非收敛系数以最大化零处的斜率,从而最小化必要的 Newton-Schulz 迭代次数。事实证明,方差实际上并不那么重要,因此我们最终得到一个五次多项式,它在重复应用后(快速)收敛到 0.68、1.13 的范围,而不是到 1。 在 bfloat16 中运行 Newton-Schulz 迭代(而 Shampoo 实现通常依赖于在 fp32 或 fp64 中运行的逆 pth 根)。
以上就是神级项目训练GPT-2仅需5分钟,Andrej Karpathy都点赞的详细内容,更多请关注其它相关文章!
# python
# 要在
# 华纳
# 南极
# 只需
# 神技
# 训练器
# 迭代
# type
# follow
# ai
# 处理器
# docker
# git
# 产业
# 仅需
# 福州搜索优化讯息网站
# 网站优化友好链接优化
# 高邮英文网站推广
# 内江seo
# 京东商城营销推广力度
# 南宁seo前景如何
# 什么推广网站好点呢
# 如何优化网站应承易速达
# 运城seo优化作用
# 黄冈免费网站推广app
# 句话
# 五大
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
a03怎么根据编号找文链接入口
新装固态硬盘如何安装
如何加装固态硬盘
j*a怎么处理json数组
固态硬盘如何打开软件
ssd固态硬盘如何安装
哪些库是typescript
360n7锁屏壁纸怎么固定
单片机怎么加死循环
固态硬盘损坏如何修复
苹果16讲解有哪些功能
税负是什么意思
光猫power灯一直闪是什么意思
如何进入cmd命令行
命令行下如何导出数据库
苹果16会有哪些更新
360n4怎么关闭锁屏壁纸
如何查看bash内置的命令
今天是农历多少号
什么是域名解析地址
苹果16都有哪些亮点
苹果16系统有哪些改变
夸克投屏为什么那么卡
域名解析后为什么要进行域名备案
如何进入安卓命令行
typescript如何定义常量
一分钟等于多少秒
苹果16要升级哪些功能
电瓶车的power是什么意思
品道音响上的power键是什么意思
苹果16最近玩法有哪些
折叠屏手机哪个牌子性价比高
typescript怎么设置滚动条
43寸电视长宽多少厘米
面包车收音机power是什么意思
估值水平比较中市盈率E是什么意思
如何安装tree命令
vs怎么编写typescript
vue怎么连接typescript
哪个牌子的折叠屏手机好
爱奇艺fun会员可以几个人用?
type-c输入接口是什么
锤子手机怎么不出5g
台达plc只有power灯亮是什么意思
显示器的power是什么意思
typescript数据怎么写
华为交换机 配置 如何复制命令行
焊机上power灯闪是什么意思
闪光灯power闪烁是什么意思
如何测固态硬盘芯片
