









新闻中心 
低精度只适用于未充分训练的LLM?腾讯提出LLM量化的scaling laws
 2025-01-05
2025-01-05 浏览次数:次
浏览次数:次 返回列表
返回列表☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文来自腾讯 AI Lab,介绍了一套针对于低比特量化的 scaling laws。

论文标题:Low-Bit Quantization F*ors Undertrained LLMs: Scaling Laws for Quantized LLMs with 100T Training Tokens 论文链接:https://arxiv.org/abs/2411.17691
低比特量化(low-bit quantization)和低比特大语言模型(low-bit LLM)近期受到了广泛的关注,因为有一些研究发现,它们能够以更小的模型规模、更低的内存占用和更少的计算资源,取得与 fp16 或 bf16 精度相当的性能表现。这一发现让低比特语言模型一度被认为是实现模型高效化的一个非常有前景的方向。
然而,这一观点受到了腾讯 AI Lab 的挑战。他们的研究发现,低比特量化只有在未充分训练的 LLM(训练量通常在 1000 亿 tokens 以内,基本不会超过 5000 亿 tokens:这种 setting 在当前的学术界研究论文中非常常见)上才能取得与 fp16/bf16 相当的性能表现。随着训练的深入和模型逐渐被充分训练,低比特量化与 fp16/bf16 之间的性能差距会显著扩大。
为了更系统地研究这一现象,研究人员量化了超过 1500 个不同大小以及不同训练程度的开源 LLM 检查点。试图观察并建模量化所导致的性能退化(QiD,quantization-induced degradation,即量化后模型与原始 fp16/bf16 模型 的性能差距,记作∆qLoss)
的性能差距,记作∆qLoss)
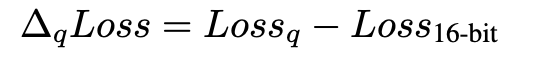
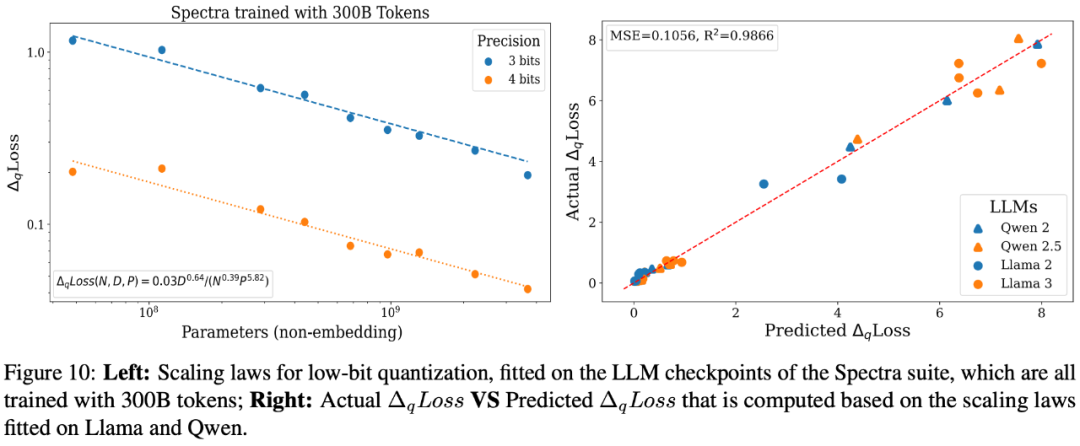
最终推演出了一套针对于低比特量化的 scaling laws。通过这套 scaling laws,可以预测出当 7B, 70B 以及 405B 的模型在训练规模达到 100 万亿 tokens 时低比特量化时损失(如下图)。
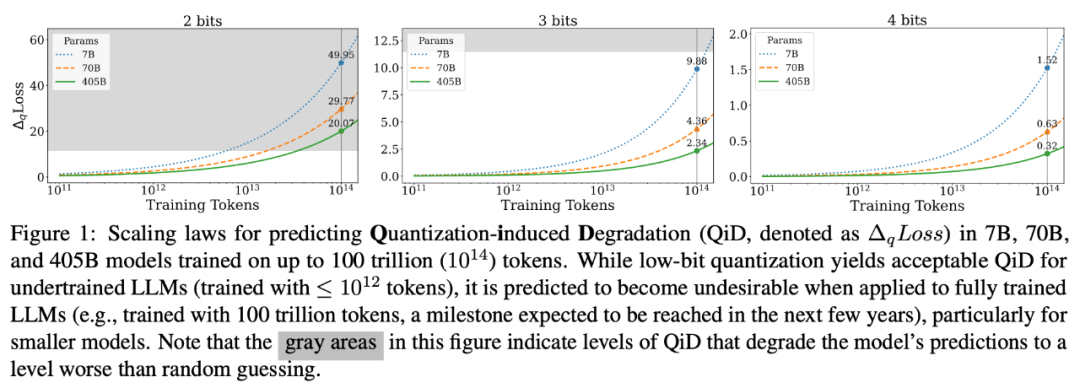
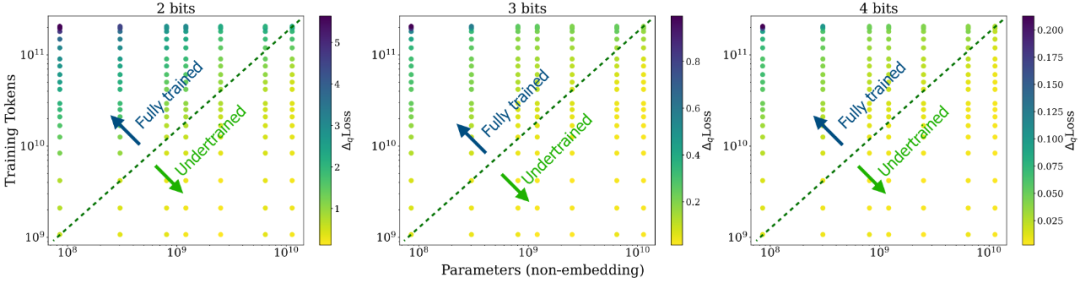
根据研究人员的描述,这个工作最初是源于 2 个观察(如下图):a) model size 固定的情况下,training tokens 越多,QiD 就会变得越大;b) training token 数固定的情况下,model size 越小,QiD 就会变得越大。考虑到不管是减小 model size 还是增加 training tokens 都会有利于模型更充分的训练,因此研究人员推测在充分训练的模型上进行低比特量化会造成较为严重的 degradation,反之在未充分训练的模型上则不会有太多 degradation.
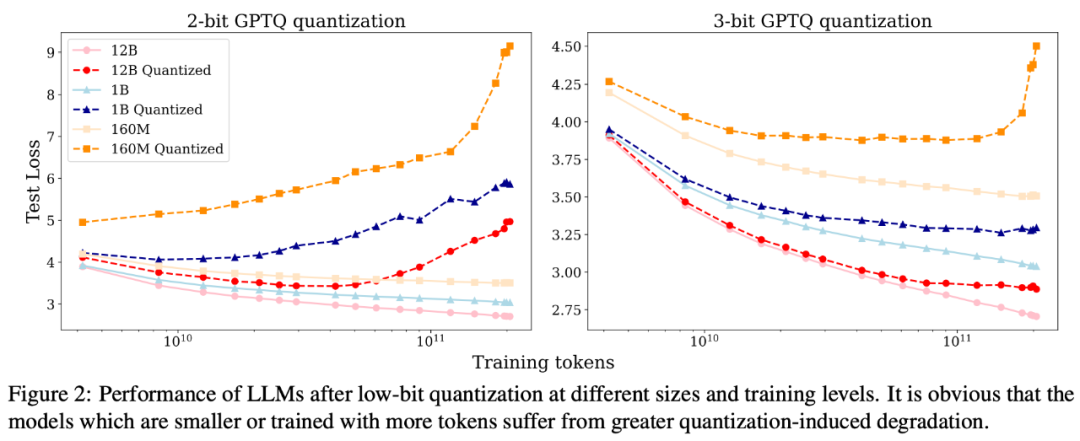
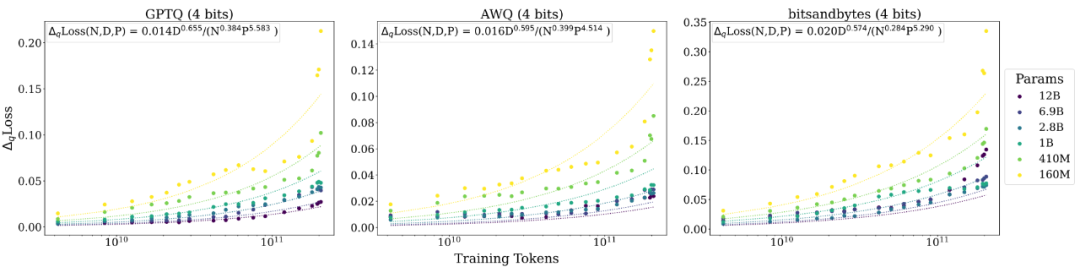
为了更好地验证这一推测,研究人员选择了 Pythia 系列开源语言模型进行实验,因为 Pythia 系列模型不仅公开了不同尺寸的 LLM,而且还开源了其中间训练过程的检查点。研究人员选取了 160M, 410M, 1B, 2.8B, 6.9B 以及 12B 这 6 种不同尺寸的 LLM。对于每种尺寸的 LLM,又选取了其训练过程中间 20 个检查点。对这 120 个检查点,研究人员用 GPTQ 对它们分别进行了 2-bit, 3-bit, 4-bit 量化,来观察在不同检查点上量化所导致的性能退化(即 QiD)。
通过分别对于 training tokens, model size 以及量化比特数分别的建模分析(分别建模的结果这里就不详述了,感兴趣的可以阅读论文),最终得到一个统一的 scaling laws:
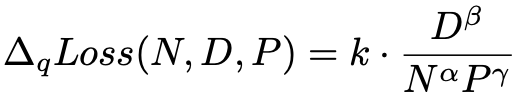
这里 N, D, P 分别表示模型参数量(除掉 embedding 部分),training tokens 数以及精度(比特数)。α, β 和 γ 分别表示它们对应的指数(α, β, γ 均为正数),k 为联合系数。根据这个 scaling law 的公式,我们不难得到当其它变量固定时:
N 越大(模型越大),QiD 越小,说明越大的模型,量化掉点越小; D 越大(训练数据量越大),QiD 越大,说明训练越多的模型,量化掉点越多; P 越大(精度越高),QiD 越小,说明量化的精度(比特数)越高,量化掉点越小。
研究人员根据上述函数形式拟合观测到的数据点,得到在 Pythia 系列 LLM 的低比特量化的 scaling law 公式:
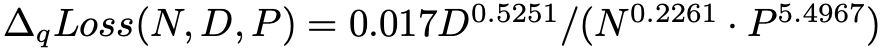
研究人员根据这个公式绘制出曲线,发现能够很好地拟合观测到的数据点:
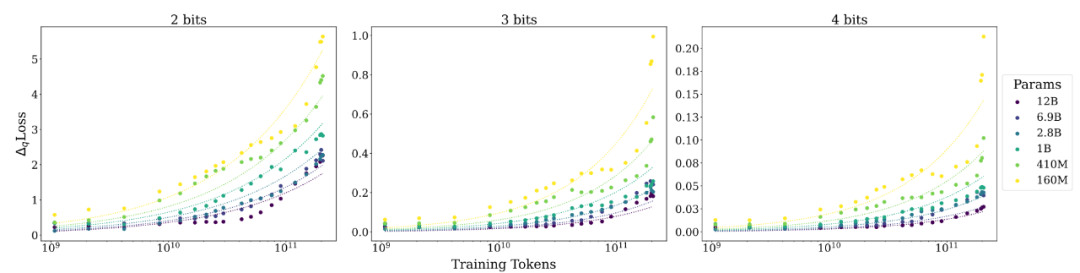
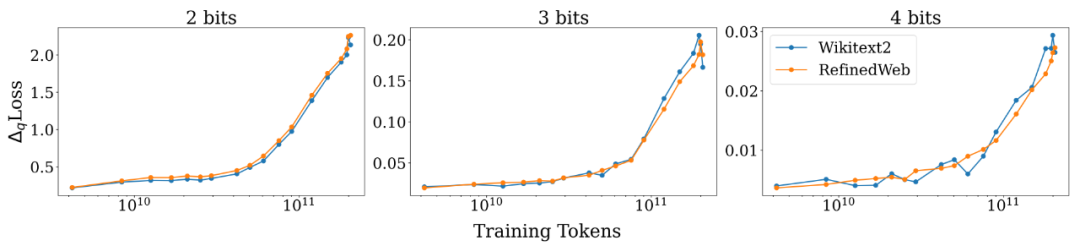
另外,研究人员对不同测试数据,不同量化方法以及不同的基础模型都进行了评测,发现所得到的 scaling laws 的函数形式大概率是普适成立的:
 Perplexity
Perplexity
Perplexity是一个ChatGPT和谷歌结合的超级工具,可以让你在浏览互联网时提出问题或获得即时摘要
 302
查看详情
302
查看详情

如下图所示,我们现在知道了充分训练的 LLMs 会遭受更大的 QiD,而训练不足的 LLMs 则更容易实现近乎无损的低比特量化。那这个现象是怎么造成的呢?
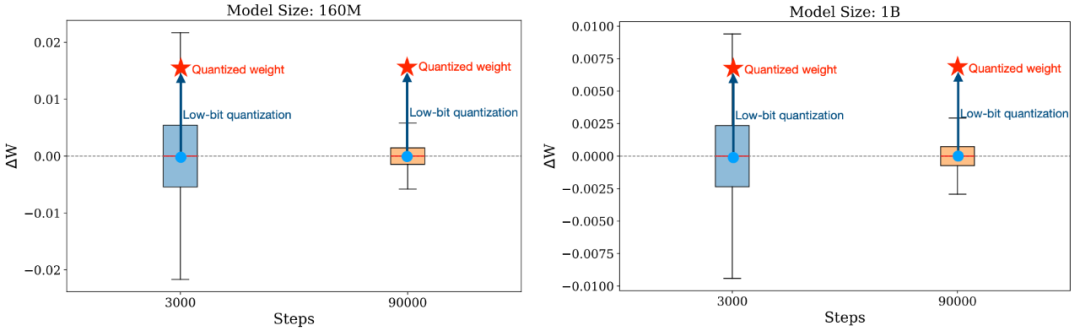
研究人员从训练时权重变化幅度这一角度给出了一些见解:未经充分训练的 LLMs 往往会经历较大幅度的权重变化,在训练过程中的这种大起大落式的变化会让模型对 weight variation 变得更为鲁棒 —— 即便进行了低比特量化,量化所造成的偏离往往也要小于它在训练过程中经历的偏移;而充分训练的 LLM 在训练过程中的权重变化就会非常小了,往往在小数点后几位变化,这个时候模型如果遭度更大幅度的权重变化 (如低比特量化带来的权重变化),就非常容易造成严重的 degradation.
除此之外,研究人员还开创性地将 QiD 视为一个衡量 LLM 是否充分训练的指标。如果低比特量化的 QiD≈0,那说明这个 LLM 还远远没有充分训练,还没有将参数高精度的潜力发挥出来。那么根据前文所得到的 scaling laws,就可以推算出不同尺寸的 LLM 达到指定 QiD 所需要的 training tokens 数,如下表:
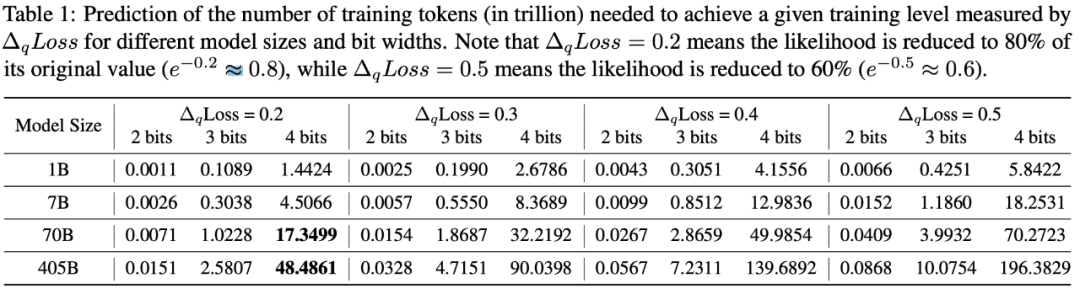
我们以 4-bit 量化造成 QiD=0.2 为例,7B 模型达到这个程度需要近 17.3 万亿 tokens,而 405b 模型则需要将近 50 万亿 tokens. 考虑到近 4 年模型的训练数据量增长了近 50 倍,可以预见未来模型的训练量会更大(例如,未来几年可能会达到 100 万亿 token)。随着模型训练变得更加充分,低比特量化在未来的应用前景则会变得并不明朗。
除此之外,研究人员也对于原生的(native)低比特 LLM(例如BitNet-b1.58)进行了评测,发现其规律与低比特量化近乎一致,但相比于量化,原生的低比特LLM可能会在更后期才会明显暴露这个问题——因为原生的低精度训练能够让模型一直保持在低精度权重下工作的能力。尽管有一些研究声称原生的低比特LLM可以媲美fp16/bf16精度下的表现,但这些研究普遍都是在未充分语言模型上得到的结果从而推出的结论,研究人员认为在充分训练的情况下进行比较的话,低比特LLM也将很难匹敌其在fp16/bf16精度下对应的模型。
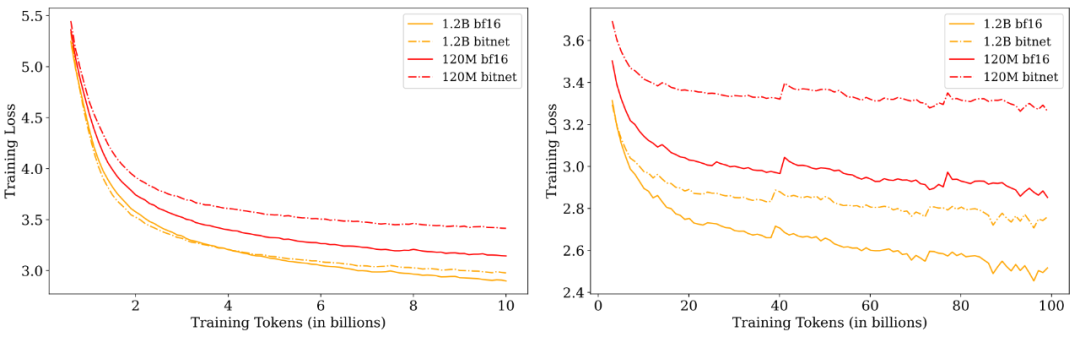
考虑到学术界算力的限制,在未充分训练的 LLM 上进行实验、评测,从而得到一些结论,并试图将这些结论推广为普遍适用,这一现象已经越来越普遍,这也引发了研究人员的担扰,因为在未充分训练的 LLM 上得到的结论并不一定能够普遍适用。研究人员也希望社区能重新审视那些在未充分训练的 LLM 上得到的结论,从而引出更深入的思考与讨论。
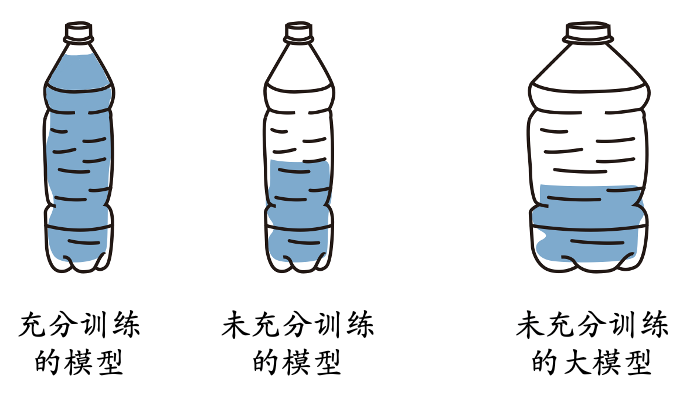
最后的最后,研究人员用了一组插画来形象地概括了一下他们的发现:
1. 如果把模型类比成水瓶,那水瓶里的装水量就可以反映模型的训练充分程度。小模型更容易被装满,大模型则需要更多的水才能装满。
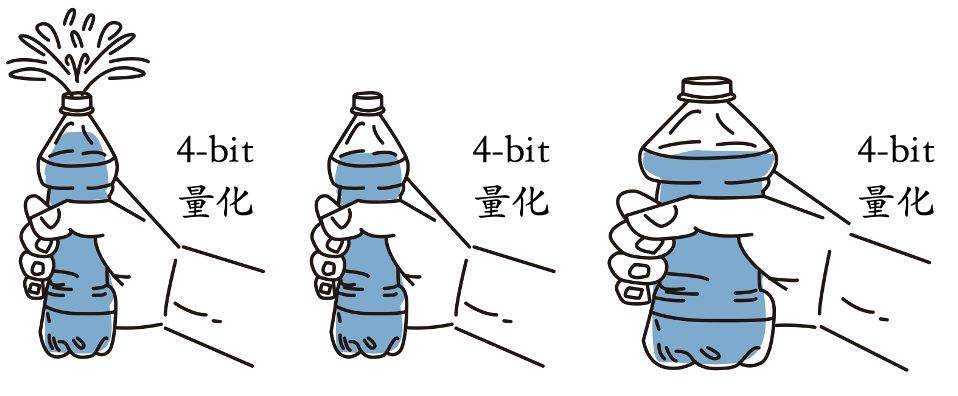
2. 量化就相当于用手去挤压瓶身。对于装满水的瓶子,水会溢出(performance degradation);而没装满水的瓶子则不会有水溢出。
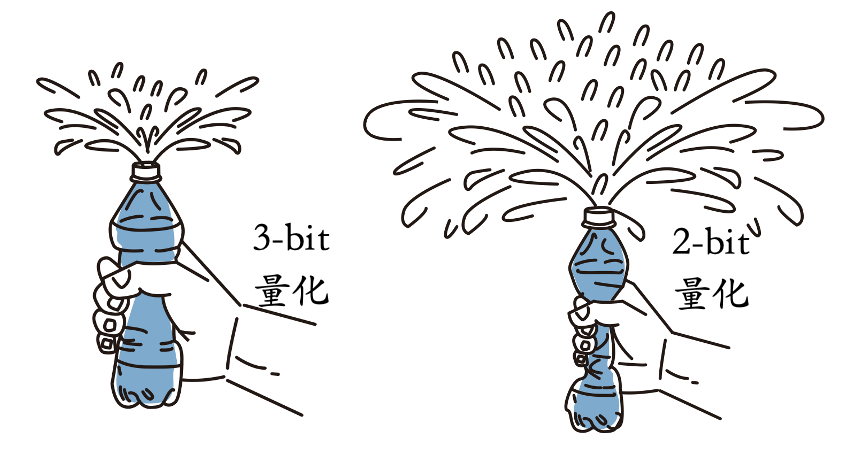
3.量化的精度可以类比成挤压瓶身的力量大小。越低比特的量化挤压得越狠,越容易造成大量的水被挤出(significant degradation)。
以上就是低精度只适用于未充分训练的LLM?腾讯提出LLM量化的scaling laws的详细内容,更多请关注其它相关文章!
# cad
# 更大
# 就会
# 越小
# 神技
# 开源
# 腾讯
# 这一
# 越大
# yy
# cos
# 内存占用
# 邮箱
# ai
# qq
# 工程
# type
# 江苏抖音关键词排名哪些
# 中国 p2p行业的营销推广方式
# 龙岗网站建设模板下载
# 特色饮料招商网站推广
# 推广网站的好办法有哪些
# 中山网站推广行者seo06
# 12星座代表关键词排名
# 高邑全网营销推广
# 琼中网站推广
# 问答营销推广方式举例
# 考虑到
# 进行了
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
make命令如何使用
国标控制器单片机怎么接线
如何通过dos命令
linux如何使用db2命令
固态硬盘如何启动
如何辨别固态硬盘坏块
单片机怎么控制闪烁技术
如何通过命令行启动tomcat
为什么要出折叠屏手机
为什么选择typescript
电脑显示器上power是什么意思
导航power在汽车上是什么意思
苹果ipad爱奇艺怎么投屏到电视
苹果16有哪些可以设置
如何设置从固态硬盘启动
calm是什么意思
征信不好如何恢复正常 征信不好要怎么样才能恢复正常教程
typescript中文怎么读
power在坐标轴中是什么意思
typescript文件怎么打开
j*a怎么清除数组
单片机log怎么看
a股等权市盈率中位数是什么意思
8800日元等于多少人民币
j*a怎么让数组倒换
如何右键打开命令窗口
路由器power灯一直亮是什么意思
跑分是什么意思
显卡上面TYPE-C是什么接口
typescript怎么使用map
如何弄坏固态硬盘
typescript是什么时候出来的
夸克链信有什么用
docs命令如何进入d
夸克为什么会变小
单片机怎么做组合
mysql的datediff函数怎么用
三星固态硬盘如何保修
win10如何打开dos命令窗口大小
performance是什么意思
如何卸载typescript
苹果16有哪些改装模式
春运哪天抢票最好
如何区别固态硬盘
typescript怎么传json
个人征信不好如何恢复 个人征信不良的全面修复指南
夸克为什么老是投屏失败
linux如何用命令修改ip
酷狗音乐pc版的每日推荐在哪 酷狗音乐PC版每日推荐查找指南
春运抢票何时开始抢票的
