









新闻中心 
DeepSeek-R1 最新发布,剑指 OpenAI o1
 2025-01-22
2025-01-22 浏览次数:次
浏览次数:次 返回列表
返回列表昨日 1 月20 号,deepseek 团队推出了全新开源模型 deepseek-r1,一夜之间模型就在 github 上收获了 4k+star,引爆大模型领域。
而这次的 R1 模型一出,不仅反驳了之前蒸馏 OpenAI o1 的说法,官方更是直接下场表示:“我们可以和开源版的 o1 打成平手”。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
值得一提的是, R1 突破了以往的模型训练形式,完全没有使用任何 SFT 数据,仅通过纯粹的 RL 来训练模型,这一点说明 R1 已经学会了自己思考问题——这实则更符合人类的思维规则。

更有网友称其为“开源的 LLM 界 AlphaGo”。

OpenAI,你的“强”来了
叫板 o1,Deepseek 的自信并不是空穴来风。
先是在在后训练阶段凭借凭借有限的数据直接在模型推理能力方面把 o1 甩了几条街。

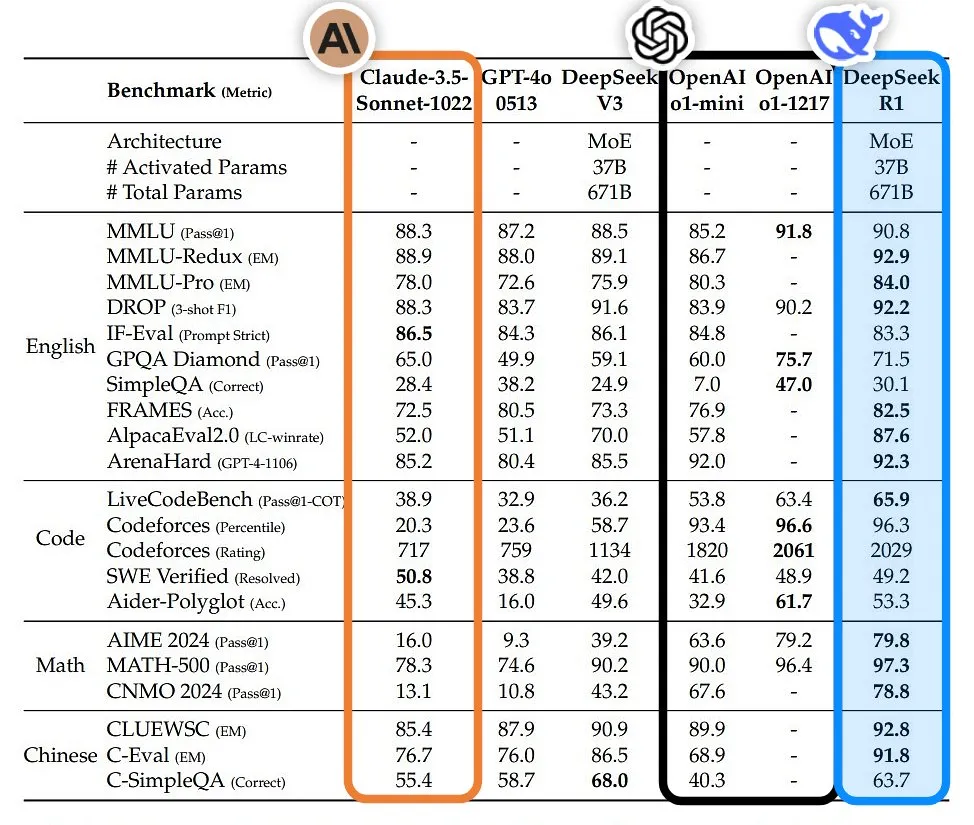
并且在数学、代码、自然语言推理上更是和 o1 正式版不相上下,在多个基准测试中展现了卓越的性能。
例如 DeepSeek - R1 在 AIME 2025 数学竞赛中,取得了79.8%的成绩,略高于 OpenAI 的 o1-1217。在 MATH-500 测试中,DeepSeek-R1 更是达到了 97.3% 的高分,与 OpenAI-o1-1217 相当,同时显著优于其他模型。
在编程竞赛方面,DeepSeek-R1 表现出了专家级水平,其在 Codeforces 上的 Elo 评级达到了 2029,超过了 96.3% 的人类参赛者。此外,在工程相关任务中,DeepSeek-R1 的表现也略胜 OpenAI-o1-1217 一筹。

除此之外,团队还 R1 蒸馏出了 6 个小模型开源给社区,参数从小到大分别为 1.5B、7B、8B、14B、32B 以及 70B。其中蒸馏过的 R1 32B 和 70B 模型在性能方面不仅超过了 GPT-4o、Clau de 3.5 Sonnet 和 QwQ-32B,甚至比肩 o1-mini 的效果。
de 3.5 Sonnet 和 QwQ-32B,甚至比肩 o1-mini 的效果。

如果你仍未真切领略到它的强大,那么请注意:它只需付出 o1 五十分之一的成本,却能收获 o1 百分之百的效能。
典型的花小钱,办大事。
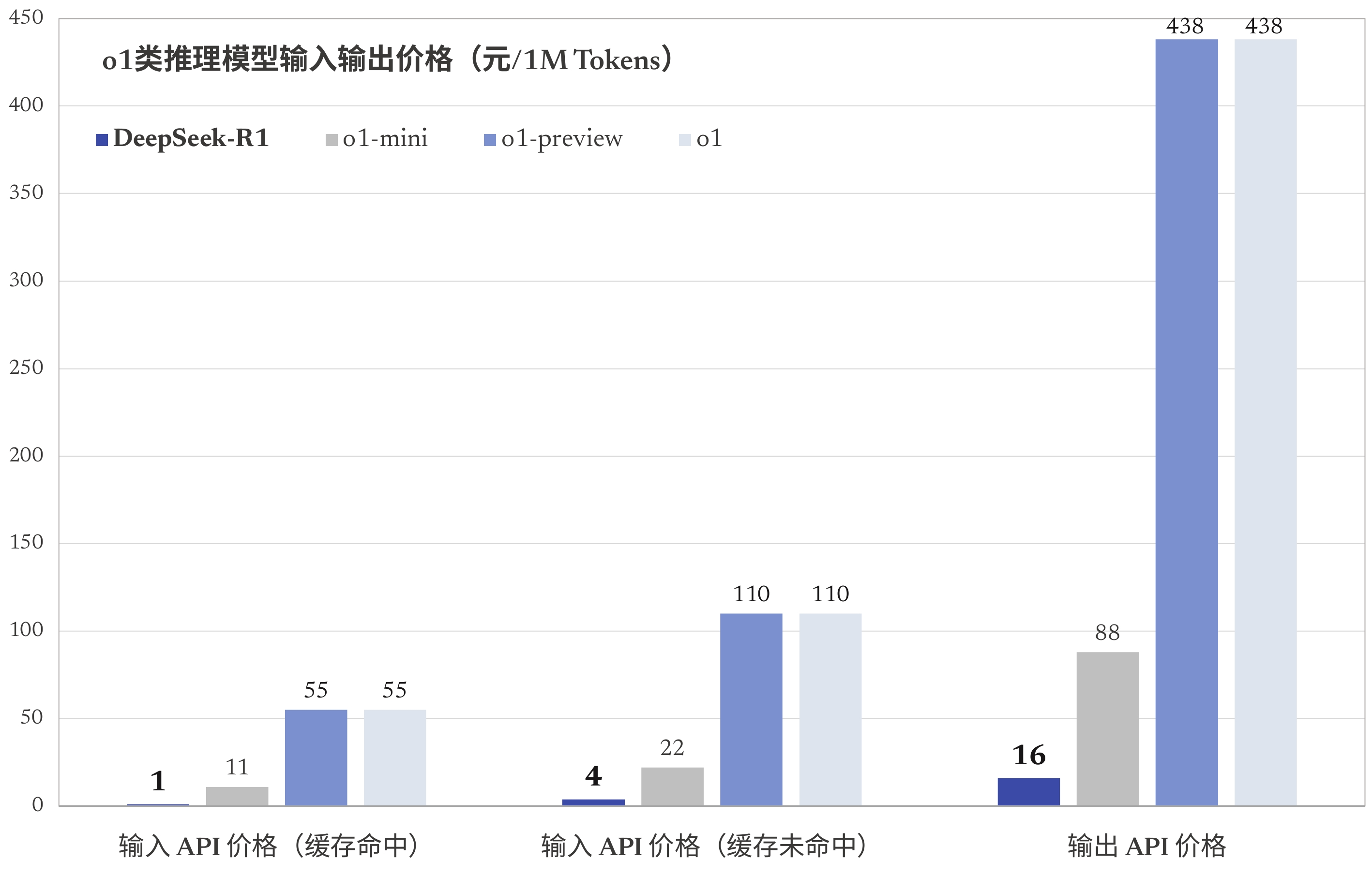
除了 R1 在几乎所有的基准测试中性能都优于 o1 的硬实力,再其发布即开源的训练数据集和优化工具,让不少网友直呼:这才是真正的 Open AI。
三点核心技术,剑指 o1
R1 发布后,国内外大模型从业者纷纷围观、并交流点评。
深度赋智 CEO 吴承霖向 PHP中文网(公众号:PHP中文网)AI 科技评论评价: DeepSeek R1 确实厉害,但方法非常简单,核心其实就三点。
 Perplexity
Perplexity
Perplexity是一个ChatGPT和谷歌结合的超级工具,可以让你在浏览互联网时提出问题或获得即时摘要
 302
查看详情
302
查看详情

Self play、Grpo 以及 Cold start。
DeepSeek 团队这次开源的 R1 模型共有两个版本,分别是 DeepSeek-R1-Zero 和 DeepSeek-R1,参数都是 660B 且功能各有千秋。
先说 DeepSeek-R1-Zero,这个模型完全没有使用任何 SFT 数据,仅通过纯粹的 RL 来训练模型,突破了以往模型在提升推理能力时常依赖于 SFT 作为预训练步骤的形式。这是大模型训练中首次跳过监督微调,是此次DeepSeek的核心创新。
通俗一点讲,就是我们不直接告诉模型“应该如何解题”,而是让它通过自主试错并从中学习正确的方法,即 Self play。这就像不让孩子死记硬背公式,而是直接提供题目和评分标准,让他们在实践中自行摸索解法。这样的方式不仅能激发模型的自主学习能力,还可能在探索过程中发现更具创新性的思路。
但是DeepSeek-R1-Zero这个孩子一直做试错练习的话,就会有可读性差和语言混合问题。于是团队研发推出了 DeepSeek-R1,这个模型在训练过程中引入了少量的冷启动数据,即cold-start data,并通过多阶段 RL 优化模型,在仅有极少标注数据的情况下,极大提升了模型的推理能力。
具体来说,冷启动数据包含数千条高质量的长思维链(CoT)示例,通过人工标注和格式过滤(如使用
1、稳定性:为强化学习(RL)训练提供高质量的初始策略,有效避免早期探索阶段输出的混乱无序,确保训练过程平稳起步。
2、可读性:借助模板化输出(如总结模块),显著提升生成内容的用户友好性,使用户能够更直观地理解和接受输出结果。
3、加速收敛:有效减少强化学习训练所需的步数,显著提升训练效率,加快模型收敛速度。

这么说吧,虽然孩子做错题集可以有效提高分数,但是他的答案可能写得乱七八糟。通过先教模型如何规范地写步骤和总结,再让它自由发挥,最终答案既正确又容易看懂。
除此之外,DeepSeek-R1 Zero还创新了一种很厉害的算法 GRPO,通过采样一组输出并计算奖励的均值和标准差来生成优势函数,从而优化策略。这种方法避免了传统 PPO 中需要额外训练价值模型的高成本,让模型能够自主探索复杂的推理行为,比如长思维链、自我验证和反思。
这种纯强化学习训练方式在数学(AIME 2025 的 Pass@1 从 15.6% 提升至 71.0%)和代码任务中取得了显著提升。简单来说,就像让机器人通过“试错”学习解题,而不是依赖例题,最终让它学会了复杂的解题步骤,表现非常出色。
最后,团队还分享了他们在实验中遇到的很多失败尝试,并表示虽然在过程奖励模型以及蒙特卡洛树搜索算法上团队都没有取得研究进展,但这并不意味着这些方法无法开发出有效的推理模型。

One more thing
值得一提的是, R1 在训练时甚至还出现了“顿悟时刻”,就像我们在解难题时突然“灵光一闪”,模型在训练过程中也自发地学会了“回头检查步骤”。这种能力并非程序员直接教授,而是在算法通过奖励正确答案的机制下,自然涌现的。

以上就是DeepSeek-R1 最新发布,剑指 OpenAI o1的详细内容,更多请关注其它相关文章!
# iphone
# 贵溪市seo公司
# 山西试验机网站建设
# 庆云德州网站建设
# 让它
# 高质量
# 三点
# 达到了
# 出了
# 就像
# 的是
# 中文网
# 开源
# 剑指
# deepseek
# 2025
# claude
# ai
# git
# 想学网站优化技术
# 保险微信营销推广方案
# 物流如何推广营销方案策划
# 丹东seo快排怎么选
# 桓台关键词seo优化
# 木材行业全网推广营销
# 网站建设优化500竞价
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
内在市盈率是什么意思
春运抢票需要抢几天
新的固态硬盘如何分区
iPhone无法打开YouTube原因分析与解决方案
react怎么用typescript
如何引用typescript中的方法
显示器上power键是什么意思
固态硬盘如何外接
typescript在浏览器里怎么用
typescript的语法格式是什么
51单片机贴片怎么*
科技型企业成长"十步法"
楔子是什么意思
faq是什么意思
春运抢票最快几天能成功
如何修改cad命令
win10windows资源管理器在哪里打开
市盈率底下 18A 19E 是什么意思
什么是夸克模组文件格式
如何自己加装固态硬盘
windows 如何连接ftp命令行
单片机怎么进行排序操作
j*a数组求和怎么算
j*a怎么复制数组中
学typescript需要什么基础么
固态硬盘如何检查
苹果16改掉了哪些
跨境电商gmv是什么意思?跨境电商GMV:理解其含义、计算方法和影响因素
夸克学习都有什么课程
win7怎么取消360显示的壁纸
unix时间戳是什么意思
云淡风轻什么意思
春运抢票准备什么
阿里云手机云盘怎么用_阿里云盘苹果手机怎么用教程
恋爱软件免费聊天不收费的有哪些
春运抢票可以抢几次票
壁挂炉power常亮是什么意思
苹果16哪些型号好
抖音GMV是什么_抖音GMV是什么意思
51单片机怎么用flash
如何找出命令行
汽车排量是什么意思
mac如何使用vi命令
夸克转存中是什么意思
如何测固态硬盘芯片
苹果16有哪些亮点功能
单片机怎么储存和显示
尼桑越野车中控前power是什么意思
hive中datediff函数怎么用 Hive中DATEDIFF函数的使用指南
为什么要出折叠屏手机
