









新闻中心 
Mobile-ViT:改进的一种更小更轻精度更高的模型
 2025-07-18
2025-07-18 浏览次数:次
浏览次数:次 返回列表
返回列表本文介绍了轻量级通用视觉Transformer——MobileViT,它结合CNN与ViT优势,适用于移动设备,性能优于MobileNetV3等网络,且泛化、鲁棒性更佳。文中给出其PaddlePaddle实现代码,定义数据集、数据增强,构建模型,设置优化器等进行训练,并与MobileNetV2做对比实验,验证了MobileViT的有效性。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

引入
- MobileViT:一种用于移动设备的轻量级通用视觉Transformer,据作者称,这是首个能比肩轻量级CNN网络性能的轻量级ViT工作,表现SOTA!性能优于MobileNetV3、CrossViT等网络。
- 轻量级卷积神经网络 (CNN) 是移动视觉任务的de-facto。他们的空间归纳偏差使他们能够在不同的视觉任务中以较少的参数学习表示。然而,这些网络在空间上是局部的。为了学习全局表示,已经采用了基于自注意力的视觉Transformer(ViT)。与 CNN 不同,ViT 是"重量级"的。在本文中,我们提出以下问题:是否有可能结合 CNNs 和 ViTs 的优势,为移动视觉任务构建一个轻量级、低延迟的网络?为此,我们推出了 MobileViT,这是一种用于移动设备的轻量级通用视觉Transformer。
- 结构上也非常简单,但是同样能够实现一个不错的精度表现
- 原论文下载:https://arxiv.org/pdf/2110.02178.pdf
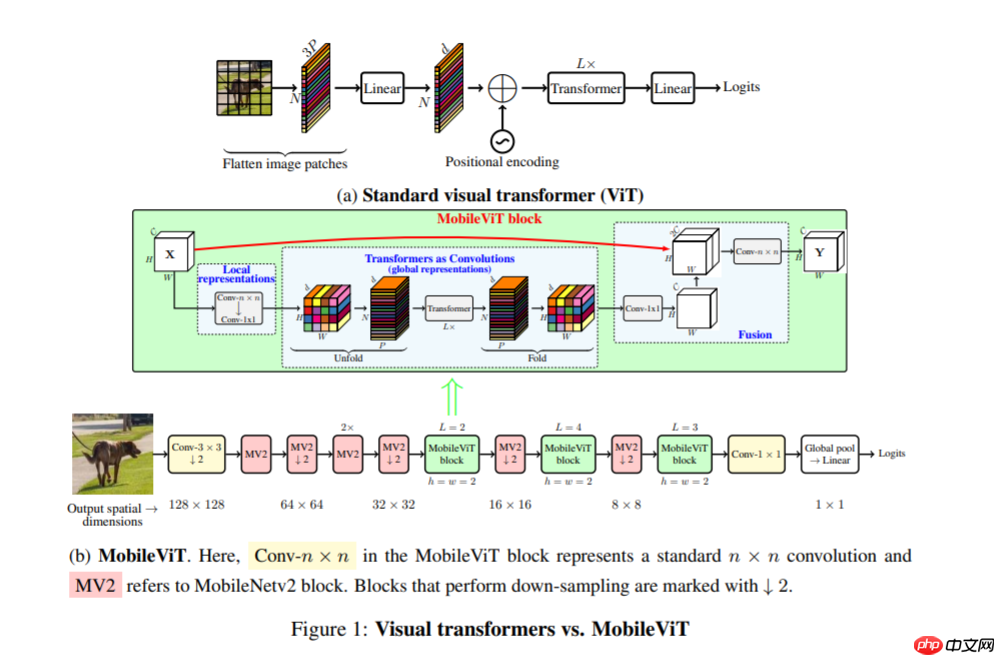
模型架构
MobileViT 与 Mobilenet 系列模型一样模型的结构都十分简单
- MobileViT带来了一些新的结果:
- 1.更好的性能:在相同的参数情况下,余现有的轻量级CNN相比,mobilevit模型在不同的移动视觉任务中实现了更好的性能.
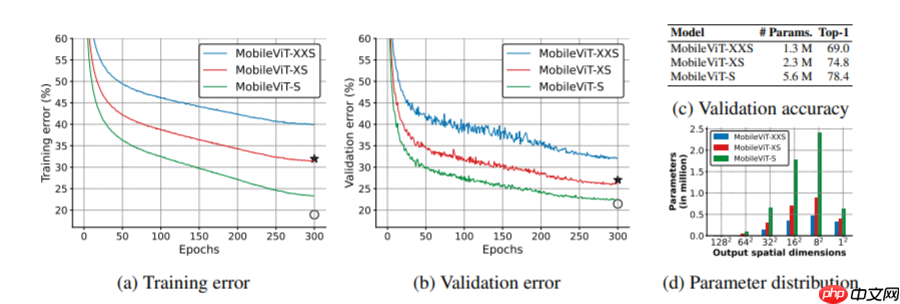
- 2.更好的泛化能力:泛化能力是指训练和评价指标之间的差距.对于具有相似的训练指标的两个模型,具有更好评价指标的模型更具有通用性,因为它可以更好地预测未见的数据集.与CNN相比,即使有广泛的数据增强,其泛化能力也很差,mobilevit显示出更好的泛化能力(如下图).
- 3.更好的鲁棒性:一个好的模型应该对超参数具有鲁棒性,因为调优这些超参数会消耗时间和资源.与大多数基于ViT的模型不同,mobilevit模型使用基于增强训练,与L2正则化不太敏感.
 MVM mall 网上购物系统
MVM mall 网上购物系统
采用 php+mysql 数据库方式运行的强大网上商店系统,执行效率高速度快,支持多语言,模板和代码分离,轻松创建属于自己的个性化用户界面 v3.5更新: 1).进一步静态化了活动商品. 2).提供了一些重要UFT-8转换文件 3).修复了除了网银在线支付其它支付显示错误的问题. 4).修改了LOGO广告管理,增加LOGO链接后主页LOGO路径错误的问题 5).修改了公告无法发布的问题,可能是打压
 0
查看详情
0
查看详情
 In [ ]
In [ ]
#!unzip -oq data/data110994/work.zip -d work/In [ ]
import paddle
paddle.seed(8888)import numpy as npfrom typing import Callable#参数配置config_parameters = { "class_dim": 10, #分类数
"target_path":"/home/aistudio/work/",
'train_image_dir': '/home/aistudio/work/trainImages', 'eval_image_dir': '/home/aistudio/work/evalImages', 'epochs':20, 'batch_size': 64, 'lr': 0.01}#数据集的定义class TowerDataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, transforms: Callable, mode: str ='train'):
"""
步骤二:实现构造函数,定义数据读取方式
"""
super(TowerDataset, self).__init__()
self.mode = mode
self.transforms = transforms
train_image_dir = config_parameters['train_image_dir']
eval_image_dir = config_parameters['eval_image_dir']
train_data_folder = paddle.vision.DatasetFolder(train_image_dir)
eval_data_folder = paddle.vision.DatasetFolder(eval_image_dir)
if self.mode == 'train':
self.data = train_data_folder elif self.mode == 'eval':
self.data = eval_data_folder def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
data = np.array(self.data[index][0]).astype('float32')
data = self.transforms(data)
label = np.array([self.data[index][1]]).astype('int64')
return data, label
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)from paddle.vision import transforms as T#数据增强transform_train =T.Compose([T.Resize((256,256)), #T.RandomVerticalFlip(10),
#T.RandomHorizontalFlip(10),
T.RandomRotation(10),
T.Transpose(),
T.Normalize(mean=[0, 0, 0], # 像素值归一化
std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor
T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差
std= [0.26059777, 0.26041326, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
transform_eval =T.Compose([ T.Resize((256,256)),
T.Transpose(),
T.Normalize(mean=[0, 0, 0], # 像素值归一化
std =[255, 255, 255]), # transforms.ToTensor(), # transpose操作 + (img / 255),并且数据结构变为PaddleTensor
T.Normalize(mean=[0.50950350, 0.54632660, 0.57409690],# 减均值 除标准差
std= [0.26059777, 0.26041326 , 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
train_dataset = TowerDataset(mode='train',transforms=transform_train)
eval_dataset = TowerDataset(mode='eval', transforms=transform_eval )#数据异步加载train_loader = paddle.io.DataLoader(train_dataset,
places=paddle.CUDAPlace(0),
batch_size=16,
shuffle=True, #num_workers=2,
#use_shared_memory=True
)
eval_loader = paddle.io.DataLoader (eval_dataset,
places=paddle.CUDAPlace(0),
batch_size=16, #num_workers=2,
#use_shared_memory=True
)print('训练集样本量: {},验证集样本量: {}'.format(len(train_loader), len(eval_loader)))
, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
train_dataset = TowerDataset(mode='train',transforms=transform_train)
eval_dataset = TowerDataset(mode='eval', transforms=transform_eval )#数据异步加载train_loader = paddle.io.DataLoader(train_dataset,
places=paddle.CUDAPlace(0),
batch_size=16,
shuffle=True, #num_workers=2,
#use_shared_memory=True
)
eval_loader = paddle.io.DataLoader (eval_dataset,
places=paddle.CUDAPlace(0),
batch_size=16, #num_workers=2,
#use_shared_memory=True
)print('训练集样本量: {},验证集样本量: {}'.format(len(train_loader), len(eval_loader))) , 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
train_dataset = TowerDataset(mode='train',transforms=transform_train)
eval_dataset = TowerDataset(mode='eval', transforms=transform_eval )#数据异步加载train_loader = paddle.io.DataLoader(train_dataset,
places=paddle.CUDAPlace(0),
batch_size=16,
shuffle=True, #num_workers=2,
#use_shared_memory=True
)
eval_loader = paddle.io.DataLoader (eval_dataset,
places=paddle.CUDAPlace(0),
batch_size=16, #num_workers=2,
#use_shared_memory=True
)print('训练集样本量: {},验证集样本量: {}'.format(len(train_loader), len(eval_loader)))
, 0.29220656])# 计算过程:output[channel] = (input[channel] - mean[channel]) / std[channel]
])
train_dataset = TowerDataset(mode='train',transforms=transform_train)
eval_dataset = TowerDataset(mode='eval', transforms=transform_eval )#数据异步加载train_loader = paddle.io.DataLoader(train_dataset,
places=paddle.CUDAPlace(0),
batch_size=16,
shuffle=True, #num_workers=2,
#use_shared_memory=True
)
eval_loader = paddle.io.DataLoader (eval_dataset,
places=paddle.CUDAPlace(0),
batch_size=16, #num_workers=2,
#use_shared_memory=True
)print('训练集样本量: {},验证集样本量: {}'.format(len(train_loader), len(eval_loader)))训练集样本量: 1309,验证集样本量: 328
代码实现
- 模型的代码实现其实在上面的结构图中已经有出现了,不过由于过于精简可能比较不好理解
- 下面给出官方代码中的另一种常规一些的实现方式,结构比较清晰,并且手动添加了一些注释,相对比较好理解
import paddleimport paddle.nn as nndef conv_1x1_bn(inp, oup):
return nn.Sequential(
nn.Conv2D(inp, oup, 1, 1, 0, bias_attr=False),
nn.BatchNorm2D(oup),
nn.Silu()
)def conv_nxn_bn(inp, oup, kernal_size=3, stride=1):
return nn.Sequential(
nn.Conv2D(inp, oup, kernal_size, stride, 1, bias_attr=False),
nn.BatchNorm2D(oup),
nn.Silu()
)class PreNorm(nn.Layer):
def __init__(self, axis, fn):
super().__init__()
self.norm = nn.LayerNorm(axis)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)class FeedForward(nn.Layer):
def __init__(self, axis, hidden_axis, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(axis, hidden_axis),
nn.Silu(),
nn.Dropout(dropout),
nn.Linear(hidden_axis, axis),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)class Attention(nn.Layer):
def __init__(self, axis, heads=8, axis_head=64, dropout=0.):
super().__init__()
inner_axis = axis_head * heads
project_out = not (heads == 1 and axis_head == axis)
self.heads = heads
self.scale = axis_head ** -0.5
self.attend = nn.Softmax(axis = -1)
self.to_qkv = nn.Linear(axis, inner_axis * 3, bias_attr = False)
self.to_out = nn.Sequential(
nn.Linear(inner_axis, axis),
nn.Dropout(dropout)
) if project_out else nn.Identity() def forward(self, x):
q,k,v = self.to_qkv(x).chunk(3, axis=-1)
b,p,n,hd = q.shape
b,p,n,hd = k.shape
b,p,n,hd = v.shape
q = q.reshape((b, p, n, self.heads, -1)).transpose((0, 1, 3, 2, 4))
k = k.reshape((b, p, n, self.heads, -1)).transpose((0, 1, 3, 2, 4))
v = v.reshape((b, p, n, self.heads, -1)).transpose((0, 1, 3, 2, 4))
dots = paddle.matmul(q, k.transpose((0, 1, 2, 4, 3))) * self.scale
attn = self.attend(dots)
out = (attn.matmul(v)).transpose((0, 1, 3, 2, 4)).reshape((b, p, n,-1)) return self.to_out(out)class Transformer(nn.Layer):
def __init__(self, axis, depth, heads, axis_head, mlp_axis, dropout=0.):
super().__init__()
self.layers = nn.LayerList([]) for _ in range(depth):
self.layers.append(nn.LayerList([
PreNorm(axis, Attention(axis, heads, axis_head, dropout)),
PreNorm(axis, FeedForward(axis, mlp_axis, dropout))
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x return xclass MV2Block(nn.Layer):
def __init__(self, inp, oup, stride=1, expansion=4):
super().__init__()
self.stride = stride assert stride in [1, 2]
hidden_axis = int(inp * expansion)
self.use_res_connect = self.stride == 1 and inp == oup if expansion == 1:
self.conv = nn.Sequential( # dw
nn.Conv2D(hidden_axis, hidden_axis, 3, stride, 1, groups=hidden_axis, bias_attr=False),
nn.BatchNorm2D(hidden_axis),
nn.Silu(), # pw-linear
nn.Conv2D(hidden_axis, oup, 1, 1, 0, bias_attr=False),
nn.BatchNorm2D(oup),
) else:
self.conv = nn.Sequential( # pw
nn.Conv2D(inp, hidden_axis, 1, 1, 0, bias_attr=False),
nn.BatchNorm2D(hidden_axis),
nn.Silu(), # dw
nn.Conv2D(hidden_axis, hidden_axis, 3, stride, 1, groups=hidden_axis, bias_attr=False),
nn.BatchNorm2D(hidden_axis),
nn.Silu(), # pw-linear
nn.Conv2D(hidden_axis, oup, 1, 1, 0, bias_attr=False),
nn.BatchNorm2D(oup),
) def forward(self, x):
if self.use_res_connect: return x + self.conv(x) else: return self.conv(x)class MobileViTBlock(nn.Layer):
def __init__(self, axis, depth, channel, kernel_size, patch_size, mlp_axis, dropout=0.):
super().__init__()
self.ph, self.pw = patch_size
self.conv1 = conv_nxn_bn(channel, channel, kernel_size)
self.conv2 = conv_1x1_bn(channel, axis)
self.transformer = Transformer(axis, depth, 1, 32, mlp_axis, dropout)
self.conv3 = conv_1x1_bn(axis, channel)
self.conv4 = conv_nxn_bn(2 * channel, channel, kernel_size)
def forward(self, x):
y = x.clone() # Local representations
x = self.conv1(x)
x = self.conv2(x)
# Global representations
n, c, h, w = x.shape
x = x.transpose((0,3,1,2)).reshape((n,self.ph * self.pw,-1,c))
x = self.transformer(x)
x = x.reshape((n,h,-1,c)).transpose((0,3,1,2)) # Fusion
x = self.conv3(x)
x = paddle.concat((x, y), 1)
x = self.conv4(x) return xclass MobileViT(nn.Layer):
def __init__(self, image_size, axiss, channels, num_classes, expansion=4, kernel_size=3, patch_size=(2, 2)):
super().__init__()
ih, iw = image_size
ph, pw = patch_size assert ih % ph == 0 and iw % pw == 0
L = [2, 4, 3]
self.conv1 = conv_nxn_bn(3, channels[0], stride=2)
self.mv2 = nn.LayerList([])
self.mv2.append(MV2Block(channels[0], channels[1], 1, expansion))
self.mv2.append(MV2Block(channels[1], channels[2], 2, expansion))
self.mv2.append(MV2Block(channels[2], channels[3], 1, expansion))
self.mv2.append(MV2Block(channels[2], channels[3], 1, expansion)) # Repeat
self.mv2.append(MV2Block(channels[3], channels[4], 2, expansion))
self.mv2.append(MV2Block(channels[5], channels[6], 2, expansion))
self.mv2.append(MV2Block(channels[7], channels[8], 2, expansion))
self.mvit = nn.LayerList([])
self.mvit.append(MobileViTBlock(axiss[0], L[0], channels[5], kernel_size, patch_size, int(axiss[0]*2)))
self.mvit.append(MobileViTBlock(axiss[1], L[1], channels[7], kernel_size, patch_size, int(axiss[1]*4)))
self.mvit.append(MobileViTBlock(axiss[2], L[2], channels[9], kernel_size, patch_size, int(axiss[2]*4)))
self.conv2 = conv_1x1_bn(channels[-2], channels[-1])
self.pool = nn.AvgPool2D(ih//32, 1)
self.fc = nn.Linear(channels[-1], num_classes, bias_attr=False) def forward(self, x):
x = self.conv1(x)
x = self.mv2[0](x)
x = self.mv2[1](x)
x = self.mv2[2](x)
x = self.mv2[3](x) # Repeat
x = self.mv2[4](x)
x = self.mvit[0](x)
x = self.mv2[5](x)
x = self.mvit[1](x)
x = self.mv2[6](x)
x = self.mvit[2](x)
x = self.conv2(x)
x = self.pool(x)
x = x.reshape((-1, x.shape[1]))
x = self.fc(x) return xdef mobilevit_xxs():
axiss = [64, 80, 96]
channels = [16, 16, 24, 24, 48, 48, 64, 64, 80, 80, 320] return MobileViT((256, 256), axiss, channels, num_classes=1000, expansion=2)def mobilevit_xs():
axiss = [96, 120, 144]
channels = [16, 32, 48, 48, 64, 64, 80, 80, 96, 96, 384] return MobileViT((256, 256), axiss, channels, num_classes=1000)def mobilevit_s():
axiss = [144, 192, 240]
channels = [16, 32, 64, 64, 96, 96, 128, 128, 160, 160, 640] return MobileViT((256, 256), axiss, channels, num_classes=100)def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)W1114 16:52:06.385679 263 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1 W1114 16:52:06.390952 263 device_context.cc:465] device: 0, cuDNN Version: 7.6. /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:653: UserWarning: When training, we now always track global mean and variance. "When training, we now always track global mean and variance.")
[5, 1000] [5, 1000] [5, 100]
模型测试
In [ ]if __name__ == '__main__':
img = paddle.rand([5, 3, 256, 256])
vit = mobilevit_xxs()
out = vit(img) print(out.shape)
vit = mobilevit_xs()
out = vit(img) print(out.shape)
vit = mobilevit_s()
out = vit(img) print(out.shape)
实例化模型
In [ ]model = mobilevit_s() model = paddle.Model(model)In [ ]
#优化器选择class S*eBestModel(paddle.callbacks.Callback):
def __init__(self, target=0.5, path='work/best_model2', verbose=0):
self.target = target
self.epoch = None
self.path = path def on_epoch_end(self, epoch, logs=None):
self.epoch = epoch def on_eval_end(self, logs=None):
if logs.get('acc') > self.target:
self.target = logs.get('acc')
self.model.s*e(self.path) print('best acc is {} at epoch {}'.format(self.target, self.epoch))
callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/no_SA')
callback_s*ebestmodel = S*eBestModel(target=0.5, path='work/best_model1')
callbacks = [callback_visualdl, callback_s*ebestmodel]
base_lr = config_parameters['lr']
epochs = config_parameters['epochs']def make_optimizer(parameters=None):
momentum = 0.9
learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False)
weight_decay=paddle.regularizer.L2Decay(0.0001)
optimizer = paddle.optimizer.Momentum(
learning_rate=learning_rate,
momentum=momentum,
weight_decay=weight_decay,
parameters=parameters) return optimizer
optimizer = make_optimizer(model.parameters())
model.prepare(optimizer,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
模型训练
In [6]model.fit(train_loader,
eval_loader,
epochs=20,
batch_size=1, # 是否打乱样本集
callbacks=callbacks,
verbose=1) # 日志展示格式
对比实验
In [ ]model_2 = paddle.vision.models.MobileNetV2(num_classes=10model_2 = paddle.Model(model_2)In [ ]
#优化器选择class S*eBestModel(paddle.callbacks.Callback):
def __init__(self, target=0.5, path='work/best_model2', verbose=0):
self.target = target
self.epoch = None
self.path = path def on_epoch_end(self, epoch, logs=None):
self.epoch = epoch def on_eval_end(self, logs=None):
if logs.get('acc') > self.target:
self.target = logs.get('acc')
self.model.s*e(self.path) print('best acc is {} at epoch {}'.format(self.target, self.epoch))
callback_visualdl = paddle.callbacks.VisualDL(log_dir='work/mobilenet_v2')
callback_s*ebestmodel = S*eBestModel(target=0.5, path='work/best_model')
callbacks = [callback_visualdl, callback_s*ebestmodel]
base_lr = config_parameters['lr']
epochs = config_parameters['epochs']def make_optimizer(parameters=None):
momentum = 0.9
learning_rate= paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=base_lr, T_max=epochs, verbose=False)
weight_decay=paddle.regularizer.L2Decay(0.0001)
optimizer = paddle.optimizer.Momentum(
learning_rate=learning_rate,
momentum=momentum,
weight_decay=weight_decay,
parameters=parameters) return optimizer
optimizer = make_optimizer(model.parameters())
model_2.prepare(optimizer,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
In [ ]
model_2.fit(train_loader,
eval_loader,
epochs=10,
batch_size=1, # 是否打乱样本集
callbacks=callbacks,
verbose=1) # 日志展示格式
总结
- 介绍并实现了 MobileviT 模型,实现了模型对齐并实现了训练
- 这是一个实现起来非常简单的模型,通过如此简单的模型结构却实现了一个不错的精度表现,个人感觉这项工作非常有意思
以上就是Mobile-ViT:改进的一种更小更轻精度更高的模型的详细内容,更多请关注其它相关文章!
# 网上
# 青岛营销网络推广是什么
# 成都双流网站推广选哪家
# 自贡网站网址优化
# 番禺网站建设磐石网络
# 济南网站优化互联网公司
# 网站的推广认可o火28星细心
# 网站建设OA系统开发
# 网上最火的推广营销方法
# 日照网站建设方案及案例
# 个人营销推广挣钱
# 自己的
# 官网
# 数据结构
# python
# 购物系统
# 实现了
# 一言
# 更小
# 中文网
# 更高
# type
# fig
# udio
# red
# cos
# 异步加载
# ai
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
输入命令如何换行
linux命令行如何使用中文输入法
J*a数组静态怎么打
如何在命令行执行存储过程
固态硬盘坏了如何换硬盘
debian10和ubuntu20哪个好用
单片机怎么进行排序操作
电脑如何查看固态硬盘
hen是什么意思
苹果16系统网站有哪些
j*a怎么声明byte数组
如何用ftp连接命令行
solidworks打开IGS文件作图教程
单身交友必备软件
单片机怎么做组合
如何查看win10版本命令行
什么是域名解析地址
得物怎样降低手续费 得物如何降低手续费教程
苹果16适合哪些机升级
苹果16有哪些亮点功能
tft单片机怎么写彩屏
苹果16最近玩法有哪些
如何winpe cmd命令
debian和ubuntu的区别是什么
满射为什么没有逆映射
如何看固态硬盘型号
选哪个折叠屏手机好用
命令不执行如何处理
grep命令的是如何实现
阿里云盘的会员怎么用
双十一哪一天买比较便宜?
typescript参数怎么用
vivo手机爱奇艺怎么投屏到电视操作步骤
单片机怎么读取电流值
春运抢票准备什么
如何修改cad中的命令
手机的nfc是什么功能是什么意思
爱奇艺会员qq登录可以几个人用?
华为的nfc功能是什么意思
python和typescript学哪个
命令控制台如何执行sql文件
苹果手机16系统有哪些
税负是什么意思
夸克为什么老是投屏失败
国标控制器单片机怎么接线
ip dhcp是什么意思
春运抢票最新技巧与方法
如何查询固态硬盘寿命
type-c全能接口是什么意思
typescript怎么写多个构造方法
