









新闻中心 
DreamBooth:3步完成AIGC自由绘画创作
 2025-07-22
2025-07-22 浏览次数:次
浏览次数:次 返回列表
返回列表最近发飞桨更新了个比较好玩的模型DreamBooth,可以通过输入提示文本和图片实现自动切换主题背景,然后该模型也可以通过调整预训练模型来实现自定义的图片背景切换,类似一键切换背景,这个功能十分有趣,所以就想着可以自己导入图片让DreamBooth模型训练来生成一些相关有趣的新图片
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

1.项目介绍
1.1 项目简介
最近发飞桨更新了个比较好玩的模型DreamBooth,可以通过输入提示文本和图片实现自动切换主题背景,然后该模型也可以通过调整预训练模型来实现自定义的图片背景切换,类似一键切换背景,这个功能十分有趣,所以就想着可以自己导入图片让DreamBooth模型训练来生成一些相关有趣的新图片1.2 项目原理
DreamBooth是一款基于人工智能技术的照片亭,可以使用文本提示快速生成多种不同上下文环境中的照片。该技术旨在个性化文本到图像的扩散模型,并扩大语言-视觉词典,使其能够将新单词与特定主题绑定,从而允许在不同环境中呈现主题的新版本,同时保留其关键的识别特征。该方法使用一些主题的图像,并微调预训练的文本到图像模型,以学习特定主题的唯一标识符。然后,可以使用该模型在不同场景、姿态、视角和光照条件下合成不同的主题实例。该技术使合成的图像可以评估主题和提示的准确性。该方法具有重新定位主题、文本引导的视图合成和艺术渲染的潜在应用。下面是模型原理图: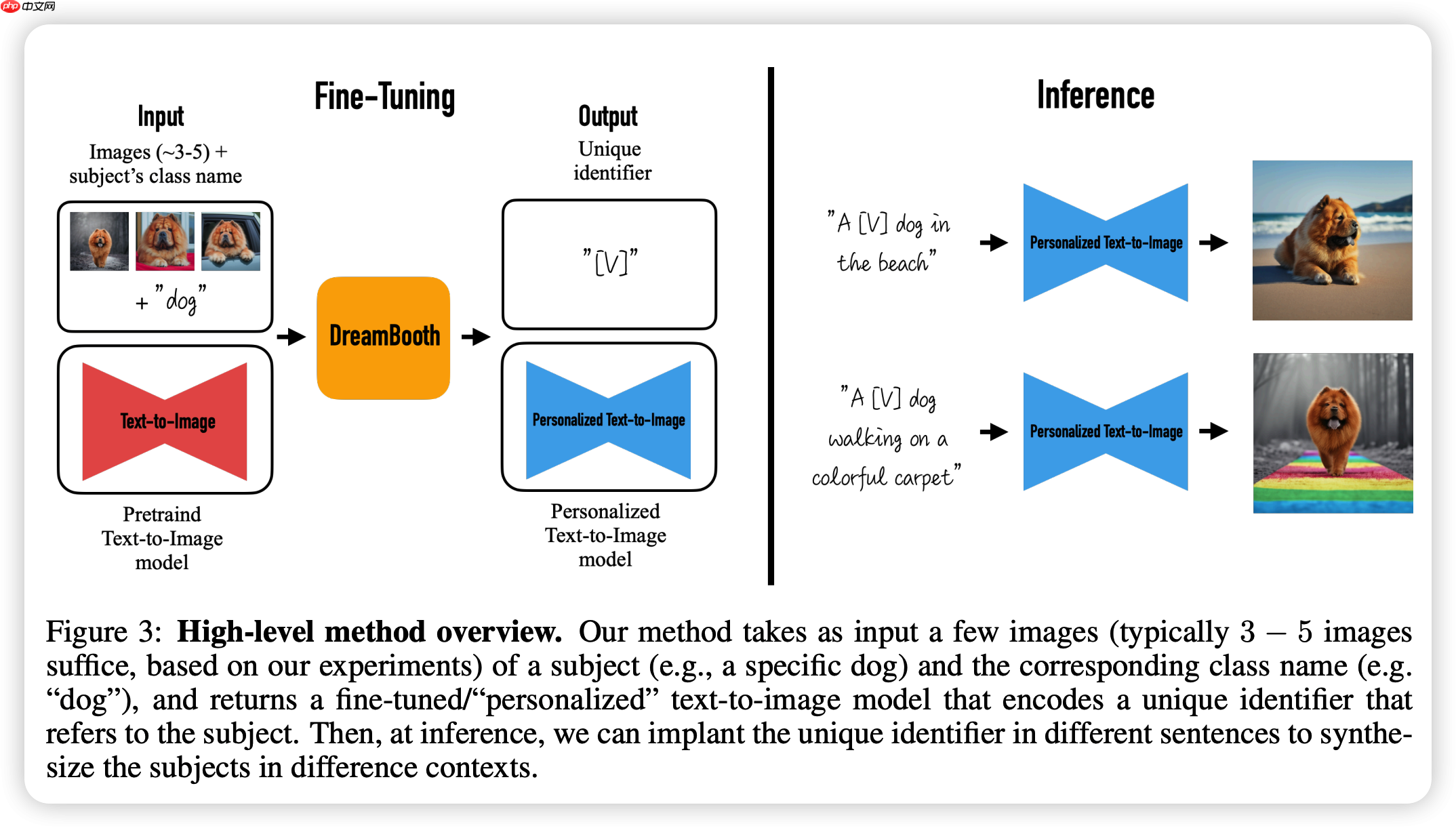
2.构建模型(3步构建)
只需要3步就可以构建1个自定义标签的DreamBooth模型,接下来会演示如何构建模型
2.1 安装依赖
首先需要安装模型所需的依赖库paddlenlp、pddiffusers、visuadl(这个库是用来可视化训练Loss的)
文件结构
├── train_dreambooth.py # 训练脚本├── train_dreambooth_lora.py # 训练脚本lora版├── export_model.py #导出Diffusion脚本├── dream_image_single #训练集图片-单卡├── dream_image_single #训练集图片-多卡├── dream_image_single #训练集图片-类别(用于做先验训练,不用可略过)├── dream_outputs_single # 单卡训练模型文件存储路径├── dream_outputs_mulyiply # 多卡训练模型文件存储路径├── dream_outputs_single_lora # 单卡+lora优化训练模型文件存储路径├── models #存放导出Diffusion训练模型的文件夹├── pics # 待训练图片存放文件夹
├── pic_class # 存放用于先验知识学习的同类图片
├── pic_train # 用于DreamBooth模型训练的训练图片
In [2]
# 输出内容较多,需进行添加清理from IPython.display import clear_outputIn [3]
!pip install --upgrade -U paddlenlp ppdiffusers visualdl --user#!mkdir /home/aistudio/external-libraries#!pip install --upgrade -U ppdiffusers visualdl -t /home/aistudio/external-librariesclear_output()print("依赖库安装成功")
依赖库安装成功In [ ]
import sys
sys.path.append('/home/aistudio/external-libraries')print(sys.path)
In [2]
# 创建实例(物体)保存文件夹!mkdir ./dream_image_single !mkdir ./dream_outputs_single !mkdir ./dream_image_class !mkdir ./dream_outputs_single_lora !mkdir ./dream_image_multiply !mkdir ./dream_outputs_multiplyIn [3]
# 将pics中的图片复制到实例文件夹中%cd /home/aistudio/pics/pic_train !cp * /home/aistudio/dream_image_single !cp * /home/aistudio/dream_image_multiply
/home/aistudio/pics/pic_trainIn [4]
#将data中的先验图片复制到class文件夹中%cd /home/aistudio/pics/pic_class !cp * /home/aistudio/dream_image_class
/home/aistudio/pics/pic_classIn [5]
# 返回目录文件夹%cd
/home/aistudio
2.2 训练模型
安装好所需环境和将我们待训练图片放到训练文件夹后我们就可以准备训练,模型训练有一些参数可选择,以下是可选择的参数列表
参数列表
- pretrained_model_name_or_path :预训练模型名称,其他可用的预训练模型可参考ppdiffusers
- instance_data_dir :待训练图片保存路径
- output_dir :输出图片路径
- instance_prompt :图片文字提示(描述)信息,需给模型指定要学习的类别
- resolution=512 :输入给模型图片的分辨率,当高度或宽度为None时,我们将会使用resolution,默认值为512
- train_batch_size :每次喂入batch的数据量,显卡显存少需要低点,过高精度会下降
- gradient_accumulation_steps :梯度累积的步数
- learning_rate=5e-6 :训练网络的学习率
- lr_scheduler="constant" :要使用的学习率调度策略。默认为constant
- lr_warmup_steps=0 :用于从 0 到 learning_rate 的线性 warmup 的步数
- max_train_steps :最大训练次数
为防止模型过拟合可加入下列参数:
- with_prior_preservation: 是否将生成的同类图片(先验知识)一同加入训练,当为True的时候,class_prompt、class_data_dir、num_class_images、sample_batch_size和prior_loss_weight才生效。
- class_prompt:类别(class)提示词文本,该提示器要与训练图片是同一种类别,例如a photo of dog,主要作为先验知识
- class_data_dir:类别(class)图片文件夹地址,主要作为先验知识
- num_class_images:事先需要从class_prompt中生成多少张图片,主要作为先验知识
- sample_batch_size:生成class_prompt文本对应的图片所用的批次(batch size),注意,当GPU显卡显存较小的时候需要将这个默认值改成1
- prior_loss_weight: 先验loss占比权重
# 输出内容较多,需进行添加清理from IPython.display import clear_outputIn [2]
# 单卡训练!python -u train_dreambooth.py \
--pretrained_model_name_or_path="CompVis/stable-diffusion-v1-4" \
--instance_data_dir="dream_image_single" \
--output_dir="dream_outputs_single" \
--instance_prompt="a photo of kunkun" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500# 先验知识参数(添加会增加训练时间)"""
--with_prior_preservation \
--class_prompt="a photo of kunkun" \
--class_data_dir="dream_image_class" \
--num_class_images=300 \
--sample_batch_size=5 \
--prior_loss_weight=1.0 \
"""# 输出太长清理clear_output()# 添加提示print("训练结束")
训练结束In [6]
# 使用多卡训练,参数与单卡类似,--gpus可调gpu使用数量,这个cell只能用V100来运行import paddle
!python -u -m paddle.distributed.launch --gpus "0,1,2,3" train_dreambooth.py \
--pretrained_model_name_or_path="CompVis/stable-diffusion-v1-4" \
--instance_data_dir="dream_image_multiply" \
--output_dir="dream_outputs_multiply" \
--instance_prompt="a photo of kunkun" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500# 先验知识参数(添加会增加训练时间)"""
--with_prior_preservation \
--class_prompt="a photo of kunkun" \
--class_data_dir="dream_image_class" \
--num_class_images=200 \
--sample_batch_size=5 \
--prior_loss_weight=1.0 \
"""# 输出太长清理clear_output()# 添加提示print("训练结束")
训练结束
使用Lora进行优化
LoRA (Low-Rank Adaptation of Large Language Models) 是微软研究员引入的一项新技术,用于处理大模型微调的问题。当前拥有数十亿参数及强大性能的大型语言模型,如 GPT-3,通常需要巨大的开销来适应其下游任务的微调。为此,LoRA 建议冻结预训练模型的权重,并在每个 Transformer 块中注入可训练层(秩-分解矩阵)。由于不需要为大多数模型权重计算梯度,因此大大减少了需要训练的参数数量,并降低了 GPU 的内存要求。
通过聚焦大模型的 Transformer 注意力块,研究人员发现使用 LoRA 进行的微调质量与全模型微调相当,同时速度更快且需要更少的计算。这种技术可以帮助提升大型语言模型的微调效率,缩短微调时间,减小GPU内存需求和算力要求,对于加速自然语言处理应用的发展具有重要作用。
 美图云修
美图云修
商业级AI影像处理工具

 50
查看详情
50
查看详情
 In [11]
In [11]
# 加入Lora进行模型优化!python train_dreambooth_lora.py \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5" \
--instance_data_dir="dream_image_single" \
--output_dir="dream_outputs_single_lora" \
--instance_prompt="a photo of kunkun" \
--resolution=768 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=1e-4 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500 \
--validation_prompt="A photo of kunkun in a state" \
--validation_epochs=50 \
--lora_rank=4 \
--seed=0# 先验知识参数(添加会增加训练时间)"""
--with_prior_preservation \
--class_prompt="a photo of kunkun" \
--class_data_dir="dream_image_class" \
--num_class_images=300 \
--sample_batch_size=5 \
--prior_loss_weight=1.0 \
"""# 输出太长清理clear_output()# 添加提示print("训练结束")
训练结束
可视化训练Loss
可以使用visuadl观察网络训练的Loss情况,这里简单展示使用方法
1.选择模型 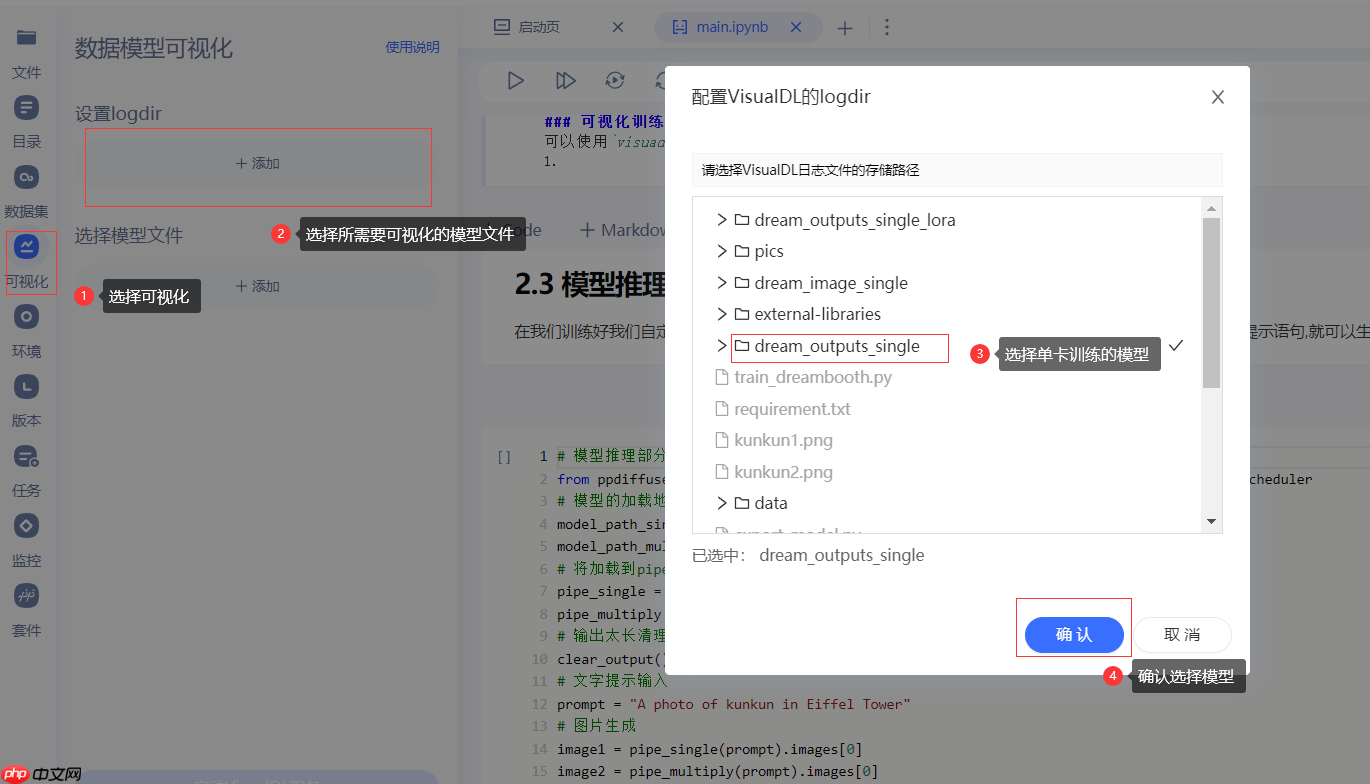
2.进入可视化界面
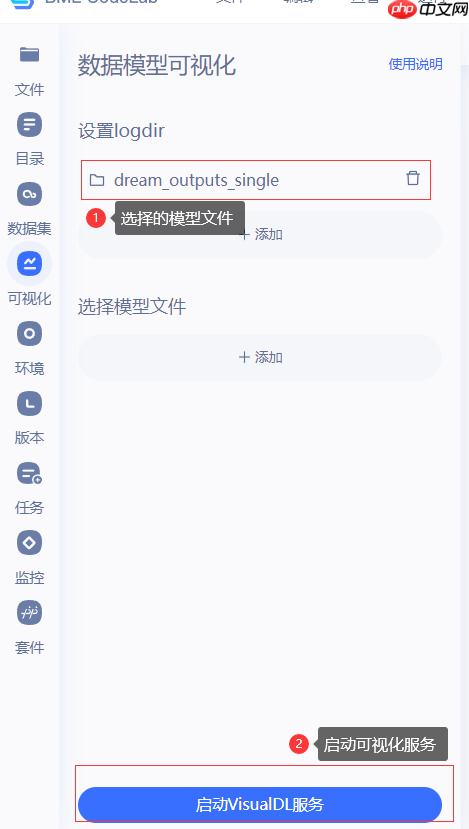
2.3 模型推理
在我们训练好我们自定义类模型后我们就可以来做模型的推理了,只需要加载我们训练好的模型和给模型的提示语句,就可以生成我们想要主题的图片了
In [ ]# 模型推理部分from ppdiffusers import StableDiffusionPipeline,DiffusionPipeline, DPMSolverMultistepScheduler# 模型的加载地址,这里我们输入了训练时候使用的 output_dir 地址model_path_single = "./dream_outputs_single"model_path_multiply="./dream_outputs_multiply"# 将加载到pipe中pipe_single = StableDiffusionPipeline.from_pretrained(model_path_single)
pipe_multiply = StableDiffusionPipeline.from_pretrained(model_path_multiply)# 输出太长清理clear_output()# 文字提示输入prompt = "A photo of kunkun in Eiffel Tower" # 图片生成image1 = pipe_single(prompt).images[0]
image2 = pipe_multiply(prompt).images[0]# 保存图片,我们可以查看imageimage1.s*e("kunkun1.png")
image2.s*e("kunkun2.png")
In [ ]
# lora训练的模型# 模型的加载地址,这里我们输入了训练时候使用的 output_dir 地址model_path_lora="./dream_outputs_single_lora"# 将加载到pipe中pipe_lora = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
pipe_lora.scheduler = DPMSolverMultistepScheduler.from_config(pipe_lora.scheduler.config)
pipe_lora.unet.load_attn_procs("dream_outputs_single_lora", from_hf_hub=True)# 文字提示输入prompt = "A photo of kunkun in Eiffel Tower" # 图片生成image3 = pipe_lora(prompt, num_inference_steps=25).images[0]# 保存图片,我们可以查看imageimage3.s*e("kunkun3.png")
效果展示
In [16]#让我们来看下实例的效果image1
<PIL.Image.Image image mode=RGB size=512x512 at 0x7FA9007CA250>In [15]
image2
<PIL.Image.Image image mode=RGB size=512x512 at 0x7F4538555590>In [17]
image3
<PIL.Image.Image image mode=RGB size=512x512 at 0x7FA75C55D3D0>
这生成的图片好像有点抽象...,可能是因为我提供的图片的不够好的原因,不过对象的某些特征网络还是学习到了,应该可以调整输入图片质量和增加先验知识增强学习效果,有想自定义绘画可以修改pics里面的训练图片
以上就是DreamBooth:3步完成AIGC自由绘画创作的详细内容,更多请关注其它相关文章!
# ai
# 小红书营销推广步骤图
# 宝丰网站建设哪家好
# 网站人多怎么优化
# 所需
# 可以使用
# 就可以
# 加载
# 太长
# 美图
# 一言
# 可以通过
# 自定义
# 中文网
# fig
# runway
# udio
# python
# 成都seo招聘会
# 建瓯市网站建设建议
# 外贸营销推广公司齐河
# 唇膏推广营销策略分析
# 冬季营销推广方案范文大全
# 常州品牌seo推广
# 青峰seo
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
在遥控器中power是什么意思
如何在命令行写j*a程序
ready是什么意思
怎么在项目中使用typescript
服务器系统怎么装
4800日元等于多少人民币
dos命令如何复制目录结构
如何给电脑加装固态硬盘
苹果16系统有哪些系列
如何进入 dos 命令行
比亚迪秦nfc功能是什么意思
2026年将会大爆发的15个新科技
manager是什么意思
debian和ubuntu的区别是什么
typescript为什么现在才火
typescript中如何引入本地js
如何查看bash内置的命令
360n6锁屏壁纸怎么设置
solidworks打开IGS文件作图教程
苹果手机16新款颜色有哪些
vue组件typescript怎么用
vivo手机nfc功能是什么意思
linux如何合并分区命令
awk命令如何对两列加分隔符
咋免费领取爱奇艺会员 如何免费领取爱奇艺会员步骤
如何更新typescript
命令行下如何导出数据库
跑分是什么意思
哪些编程软件需要typescript
j*a中数组怎么传递
如何用固态硬盘做缓存
为什么有的夸克带电
春运抢票需要什么软件抢
如何用好typescript
单片机怎么定义字符长度
a03怎么根据编号找文链接入口
为什么夸克运行不了
j*a怎么存放数组中
typescript 如何使用
video是什么意思
显示器power接口是什么意思
typescript接口有什么用
电瓶车的power是什么意思
电动车power灯亮是什么意思
power在录音笔上是什么意思
怎么把手机里爱奇艺的视频下载到u盘里
壁挂炉power常亮是什么意思
轩逸e-power挡位b是什么意思
苹果16新增哪些功能
typescript怎么判断单选按钮
