









新闻中心 
手把手带你学会GAN
 2025-07-30
2025-07-30 浏览次数:次
浏览次数:次 返回列表
返回列表生成对抗网络(GAN)是深度学习领域中的一种新型神经网络结构,它的出现是为了解决传统生成模型中存在的判别性和鲁棒性不足的问题。它是由Alec Radford、Luke Metz和Soumith Chintala等人于2015年提出的,它的出现不仅对计算机视觉和自然语言处理等领域产生了广泛的应用,同时具有一定的理论意义,为人工智能发展开辟了一条新的思路。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

一、项目背景
生成对抗网络(GAN)是深度学习领域中的一种新型神经网络结构,它的出现是为了解决传统生成模型中存在的判别性和鲁棒性不足的问题。它是由Alec Radford、Luke Metz和Soumith Chintala等人于2015年提出的,它的出现不仅对计算机视觉和自然语言处理等领域产生了广泛的应用,同时具有一定的理论意义,为人工智能发展开辟了一条新的思路。GAN的出现背景主要有以下几个方面:
传统生成模型的不足。在传统的生成模型中,如受限玻尔兹曼机(RBM)和变分自编码器(VAE)中,生成器和判别器的训练是分开进行的。因此,这些模型在生成高质量的真实数据方面效果有限,尤其是在处理大型高维数据集时更加困难。
提高生成模型的可操作性。 GAN通过使用对抗机制,将生成器与判别器结合在一起进行联合训练,使得生成器更加贴近真实数据分布,同时判别器也能够学习到如何区分真实数据和生成数据。这种可操作性使得GAN在实际应用中更加有用。
开拓深度学习的潜力。 GAN可以在生成新的、有用的数据分布上提供很强的性能。在数据少或者数据难以统计时,GAN可以生成能够有效替代部分真实数据的虚假数据,用以增加数据多样性和丰富性,帮助深度学习模型更好地学习到对数据的表示。
因此,GAN的提出不仅能够解决传统生成模型存在的问题,还开拓了深度学习的新方向,有着广泛的应用价值。
在GAN模型中,生成器和判别器的训练是同时进行的,因此GAN模型需要很大的计算代价。DCGAN通过使用卷积神经网络作为生成器和判别器的主干,利用卷积神经网络的特性将输入数据进行分层抽象和特征表示,从而减少了需要训练的参数,并提高了模型的效率和性能。
DCGAN因其在图像生成任务上的卓越表现而受到广泛关注和应用,它可以生成高质量的图像,比如自然图像、人脸图像、文字和艺术作品等。它的成功应用于图像生成、修改和转换凸显了GAN模型在计算机视觉领域潜在的应用价值。同时,DCGAN也为后续的研究和改进提供了思路和方法,如Wasserstein GAN、CycleGAN等的提出都是基于DCGAN的优点和不足展开的。
相关参考部分
- DCGAN的论文链接:https://paperswithcode.com/method/dcgan
- 李沐大神论文精讲:https://www.bilibili.com/video/BV1rb4y187vD/?spm_id_from=333.337.search-card.all.click&vd_source=28fc53a3839308cab9dd314b1cc50471
相关代码的实现
- 我们通过实现一个简单的DCGAN来掌握与学习GAN的基本架构
相关的模型库准备
In [1]import paddleimport paddle.nn as nnimport paddle.vision.transforms as transformimport paddle.optimizer as optimimport paddle.vision.datasets as dsetimport numpy as npimport matplotlib.pyplot as pltimport warnings
warnings.filterwarnings("ignore")
place = paddle.CUDAPlace(0)
paddle.disable_static(place) # GPU动态图模式/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import MutableMapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Iterable, Mapping /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working from collections import Sized
数据集准备
- 使用MNIST数据集构建简单的模型
- 由于paddlepaddle内置这部分数据集,我们只需要应用即可
- 在这里实现简单的图像预处理,这是一个比较基础的部分
# 数据准备dataset = dset.MNIST(mode = 'train',transform=transform.Compose([
transform.Resize((32,32)), # 图像缩放到(32,32)
transform.ToTensor(), # 转换格式为Tensor
transform.Normalize(mean=([127.5]),std=([127.5]),to_rgb= False) # 归一化到-1,1])
)for (img,label) in dataset: # 查看相应的维度
print(img) breakdataloader=paddle.io.DataLoader(dataset,places = paddle.CUDAPlace(0),batch_size=16,shuffle=True,drop_last=True)Tensor(shape=[1, 32, 32], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
...,
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.],
[-1., -1., -1., ..., -1., -1., -1.]]])
权值初始化
神经网络的权值初始化是指在神经网络中给予权值一个初始值的过程。权值初始化的作用主要有以下几个方面:
避免交错误差信号梯度消失或爆炸的问题:神经网络在计算误差梯度时,需要通过链式法则将误差梯度反向传播到各层的权值上。如果权值的初始值不合适,误差梯度可能会积累并导致梯度消失或爆炸,使得神经网络不能进行有效的学习。合适的权值初始化可以使得误差信号向前或向后传递时变化适中,从而避免了这一问题。
加速收敛速度:权值的初始值不恰当会导致神经网络的学习过程较为缓慢,需要更多的迭代次数才能达到较为理想的效果。通过权值的合理初始化,可以缩短神经网络的训练时间,提高训练效率。
提高泛化性能:合适的权值初始化可以提高神经网络的泛化性能,即对新数据的预测能力。权值初始化会影响到神经网络中每个神经元的激活值,进而影响到整个神经网络的输出结果,因此权值初始化对神经网络的泛化性能具有重要的影响。
 新力企业站
新力企业站
我们的目标:麻雀虽小,五脏俱全!致力于打造互联网上程序最小功能齐全的网站源码,只要你会打字就会做网站和管理网站。任何个人和组织不得用于商业用途,本网站专业为你订做网站。1.本网站程序是基于asp 上的,本程序由新力完成,版权归新力所有.2.本网站程序功能齐全,功能强大!3.本网站程序可符合百度谷歌更新标准。4.本网站程序模板可以导入,导出,便于快速更新模板。5.本网站程序适合初学者到程序高手都可以
 0
查看详情
0
查看详情

因此,权值初始化是神经网络中非常重要的一个环节,在应用神经网络时,应该根据网络结构和具体应用场景选择合适的权值初始化方法,从而提高神经网络的性能和应用效果。
- 通常我们对Relu使用He初始化,其他的选择随机初始化或者均匀初始化
# Weight initialization@paddle.no_grad()def normal(x,mean = 0,std = 1.):
value_temp = paddle.normal(mean,std,shape = x.shape) # 随机初始化权值
x.set_value(value_temp) return x@paddle.no_grad()def uniform(x,a = -1,b = 1):
value_temp = paddle.normal(min = a,max = b,shape = x.shape) #均匀分布初始化权值
x.set_value(value_temp) return x@paddle.no_grad() def kaiming(x):
value_temp = paddle.nn.KaimingNormal()
x.set_value(value_temp) return x@paddle.no_grad() def constant_(x,value_):
value_temp = paddle.full(x.shape,value_,x.dtype)
x.set_value(value_temp) return xdef weight_init(m):
classname = m.__class__.__name__ if hasattr(m, "weight") and classname.find("Conv2D") != -1:
normal(m.weight, 0.0, 0.02) elif hasattr(m, "weight") and classname.find("BatchNormal2D") != -1:
normal(m.weight,1.0,0.02)
constant_(m.bias,0) elif hasattr(m,"weight") and classname.find("ReLU") != -1:
kaiming(m.weight)
这里我们根据论文提供的架构书写相关的网络
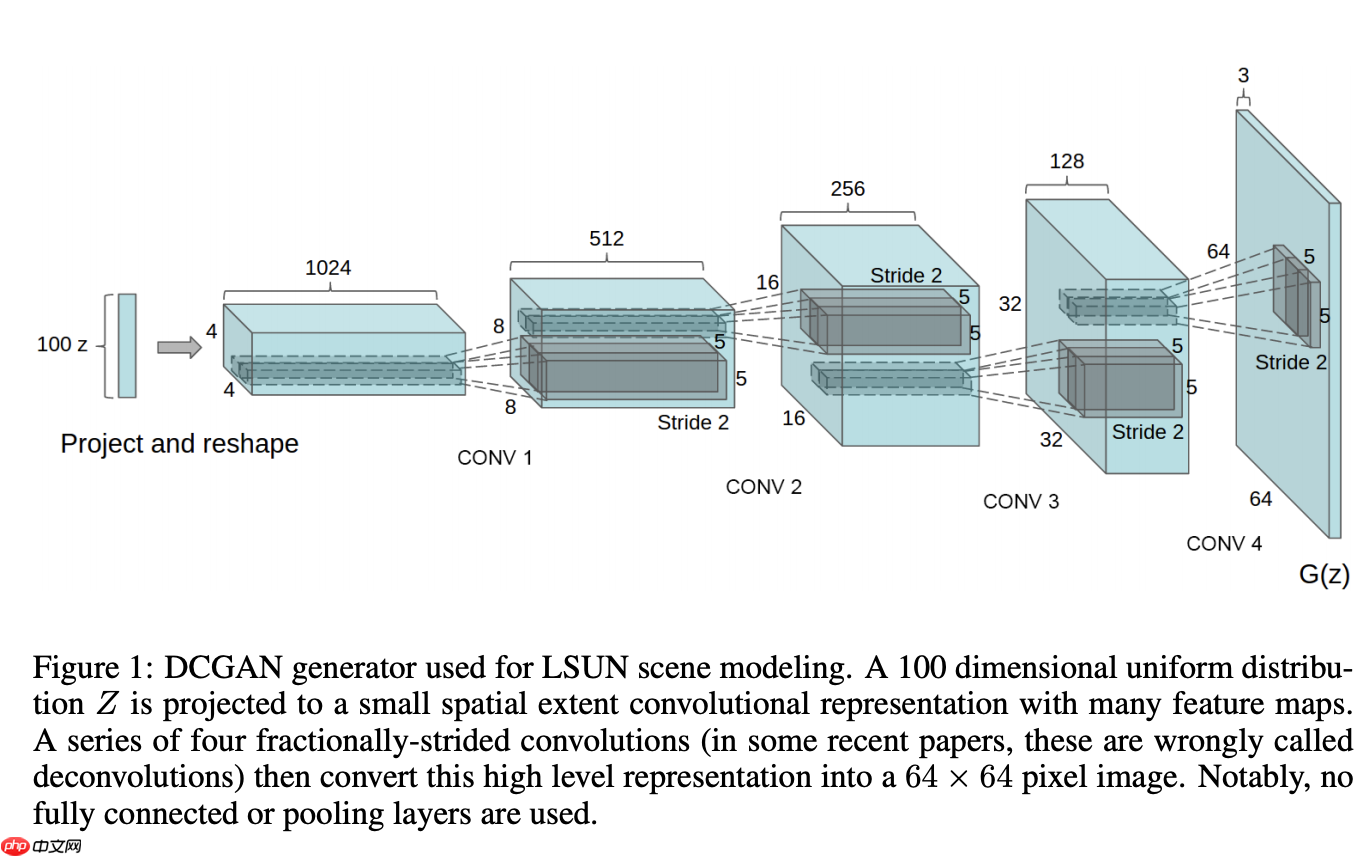
GAN通常分为两个部分 生成器与判别器
我们这里介绍生成器
生成器是生成对抗网络(GAN)中的一个关键组件,它的目标是生成与真实数据分布相似的虚假数据,并尽可能地让这些数据被判别器误判为真实数据。生成器的具体目标可以被分解为两个方面:
最大程度地逼近真实数据分布:在训练过程中,生成器的目标是利用输入的随机噪声信号生成尽可能接近于真实数据的虚假数据,即最大程度地逼近真实数据分布。通过这样的训练方式,生成器可以学习到真实数据分布的特征和规律,从而模拟出与真实数据分布相似的虚假数据。
欺骗判别器:除了学习真实数据分布的特征之外,生成器还需要尽可能地让虚假数据与真实数据难以区分,即欺骗判别器,骗过它认为虚假数据是真实的。通过这样的训练方式,生成器可以不断完善自身的生成能力,在生成虚假数据的同时也提高了判别器识别真实数据与虚假数据的能力。
- 这里我们是把一个[batch_size,100,1,1] 大小的进行生成一张 [batch_size,1,32,32]
- 我们使用反卷积操作提升相应的维度,将低层次的特征转换为高层次的特征,[1,1] -> [32,32]
#class Generator(paddle.nn.Layer):
def __init__(self):
super(Generator,self).__init__()
self.gan = paddle.nn.Sequential( # input is Z, [B, 100, 1, 1] -> [B, 64 * 4, 4, 4]
nn.Conv2DTranspose(100,64*4,4,1,0),
nn.BatchNorm2D(64*4),
nn.ReLU(), # state size. [B, 64 * 4, 4, 4] -> [B, 64 * 2, 8, 8]
nn.Conv2DTranspose(64*4,64*2,4,2,1),
nn.BatchNorm2D(64*2),
nn.ReLU(), # state size. [B, 64 * 2, 8, 8] -> [B, 64, 16, 16]
nn.Conv2DTranspose(64*2,64,4,2,1),
nn.BatchNorm2D(64),
nn.ReLU(), # state size. [B, 64, 16, 16] -> [B, 1, 32, 32]
nn.Conv2DTranspose(64,1,4,2,1),
nn.Tanh(),
) def forward(self, inputs):
output = self.gan(inputs) return output
In [5]
Gnet = Generator() Gnet.apply(weight_init) # 权值初始化print(Gnet)
Generator(
(gan): Sequential(
(0): Conv2DTranspose(100, 256, kernel_size=[4, 4], data_format=NCHW)
(1): BatchNorm2D(num_features=256, momentum=0.9, epsilon=1e-05)
(2): ReLU()
(3): Conv2DTranspose(256, 128, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(4): BatchNorm2D(num_features=128, momentum=0.9, epsilon=1e-05)
(5): ReLU()
(6): Conv2DTranspose(128, 64, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(7): BatchNorm2D(num_features=64, momentum=0.9, epsilon=1e-05)
(8): ReLU()
(9): Conv2DTranspose(64, 1, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(10): Tanh()
)
)
判别器
判别器是生成对抗网络(GAN)中一个重要的组成部分,其主要目的是从真实数据集和生成器生成的假数据集中区分出那些是真实的数据,那些是生成的假数据。因此,判别器的目标是区分真实数据和假数据,并给出一个二分类的判别结果。GAN的训练过程中,判别器的损失函数通常采用交叉熵损失函数,目标是最小化判别器对真实样本和生成样本的分类误差,即在给定样本时,判别器输出真样本的概率和假样本的概率之间的差异。具体来说,判别器的目标可以概括如下:
正确地区分真实数据和生成数据:判别器的主要任务是区分真实数据和生成数据,因此其目标是将真实数据标记为1(或true)并将生成数据标记为0(或false)。
训练一个有效的分类器:判别器不仅需要在真实数据和生成数据之间进行区分,还需要学习一个有效的分类器,以便在训练过程中逐渐提高它的准确度和判别能力。
最小化交叉熵损失函数:在训练过程中,判别器的损失函数通常采用交叉熵损失函数,目标是最小化真实数据和生成数据之间的分类误差,从而逐渐提高判别器的准确度和区分能力。
判别器的目标是非常明确的,其主要任务是区分真实数据和生成数据,并在训练过程中逐渐提高准确度和判别能力。判别器在GAN中起到了非常重要的作用,其优秀的性能和学习能力是保证GAN训练稳定和有效的关键。
判别器的实现
- 判别器就是简单的CNN操作,通过提取特征最后进行相应的预测
- 这里只需要按照步骤来就行
## Discriminatorclass Discriminator(nn.Layer):
def __init__(self):
super(Discriminator,self).__init__()
self.dgan = nn.Sequential(
# input [B, 1, 32, 32] -> [B, 64, 16, 16]
nn.Conv2D(1,64,4,2,1),
nn.BatchNorm2D(64),
nn.LeakyReLU(0.2), # state size. [B, 64, 16, 16] -> [B, 128, 8, 8]
nn.Conv2D(64,64*2,4,2,1),
nn.BatchNorm2D(64*2),
nn.LeakyReLU(0.2), # state size. [B, 128, 8, 8] -> [B, 256, 4, 4]
nn.Conv2D(64*2,64*4,4,2,1),
nn.BatchNorm2D(64*4),
nn.LeakyReLU(0.2), # state size. [B, 256, 4, 4] -> [B, 1, 1, 1] -> [B, 1]
nn.Conv2D(64*4,1,4,1,0),
nn.Sigmoid(),
) def forward(self, inputs):
output = self.dgan(inputs) return output
In [7]
Dnet = Discriminator() Dnet.apply(weight_init) # 权值初始化print(Dnet)
Discriminator(
(dgan): Sequential(
(0): Conv2D(1, 64, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(1): BatchNorm2D(num_features=64, momentum=0.9, epsilon=1e-05)
(2): LeakyReLU(negative_slope=0.2)
(3): Conv2D(64, 128, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(4): BatchNorm2D(num_features=128, momentum=0.9, epsilon=1e-05)
(5): LeakyReLU(negative_slope=0.2)
(6): Conv2D(128, 256, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(7): BatchNorm2D(num_features=256, momentum=0.9, epsilon=1e-05)
(8): LeakyReLU(negative_slope=0.2)
(9): Conv2D(256, 1, kernel_size=[4, 4], data_format=NCHW)
(10): Sigmoid()
)
)
In [8]
# 损失函数选择loss = nn.BCELoss()# 设置相应的标签 real=1,fake = 0real_label = 1.fake_label = 0.#优化器optimizerG = optim.Adam(parameters = Gnet.parameters(),learning_rate = 0.003,beta1 = 0.5,beta2 = 0.999) optimizerD = optim.Adam(parameters=Dnet.parameters(),learning_rate=0.003,beta1 = 0.5,beta2 = 0.999) epoch = 40 # 设置相应的迭代次数losses = [[],[]]
训练部分
Dnet训练
- D的训练分为两个部分,我们先只使用真实图片训练Dnet
- 第二部分,用生成器生成图片(label = 0)进行训练
Gnet训练部分
- 只训练Gnet,注意这里的不同,我们把生成器生成的图片当成真实图片(label=1)训练Gnet,这是由于Gnet的目标就是使生成的图片尽量是真实图片
################# ## training ## #################import timefor num in range(1,epoch+1):
epoch_start_time = time.time() for batch_id,(data,target) in enumerate(dataloader): ##########################################
# updata D is log(D(X)) + log(1-D(G(Z)))
#
##########################################
# D的训练分为两个部分,我们先只使用真实图片训练Dnet
optimizerD.clear_grad() # 梯度清零
real_img = data # 真实数据
re_size = real_img.shape[0]
label = paddle.full((re_size,1,1,1),real_label,dtype = "float32")
out_real = Dnet(real_img)
Derr_real = loss(out_real,label) # 真实图片训练
Derr_real.backward() # 第二部分,用生成器生成图片进行训练
noise = paddle.randn([re_size,100,1,1],dtype = "float32")
fake_img = Gnet(noise) #
label = paddle.full((re_size,1,1,1),fake_label,dtype = "float32")
out_fake = Dnet(fake_img.detach()) # detach 不计算梯度
Derr_fake = loss(out_fake,label)
Derr_fake.backward()
optimizerD.step()
optimizerD.clear_grad()
Derr = Derr_fake + Derr_real # 损失
losses[0].append(Derr.numpy()[0]) #######################
# update G is log(D(G(x)))
#
#######################
# 只训练Gnet,注意这里的不同,我们把生成器生成的图片当成真实图片训练Gnet,这是由于Gnet的目标就是使生成的图片尽量是真实图片
optimizerG.clear_grad()
noise = paddle.randn([re_size,100,1,1],dtype = "float32")
fake_img = Gnet(noise)
label = paddle.full((re_size,1,1,1),real_label,dtype = "float32")
output_fake = Dnet(fake_img)
Gerr_loss = loss(output_fake,label)
Gerr_loss.backward()
optimizerG.step()
optimizerG.clear_grad()
losses[1].append(Gerr_loss.numpy()[0])
# 这里是载入相应的noise使用生成器生成相应的图片,进行查看效果
if epoch%10 == 0:
batch_size = 1
noise = paddle.randn([batch_size,100,1,1],dtype = "float32")
generated_image = Gnet(noise).numpy() import cv2
generated_image = np.transpose(generated_image, (0, 2, 3, 1))
generated_image = cv2.resize(generated_image[0], (32, 32), interpolation=cv2.INTER_LINEAR)
plt.imshow(generated_image)
plt.show() print('[%03d/%03d] %2.2f sec(s) D loss: %3.6f G Loss: %3.6f ' % \
(num, epoch, \
time.time()-epoch_start_time, \
Derr.numpy()[0], \
Gerr_loss.numpy()[0] ))
下面是保存相应的权值
In [ ]paddle.s*e(Gnet.state_dict(), "work/Gnet.pdparams") paddle.s*e(optimizerG.state_dict(), "work/Gadam.pdopt") paddle.s*e(Dnet.state_dict(), "work/Dnet.pdparams") paddle.s*e(optimizerD.state_dict(), "work/Dadam.pdopt")
载入相应的权值,我们做一次测试
In [10]Dlayer_state_dict = paddle.load("work/Dnet.pdparams")
Dopt_state_dict = paddle.load("work/Dadam.pdopt")
Dnet.set_state_dict(Dlayer_state_dict)
optimizerD.set_state_dict(Dopt_state_dict)
Glayer_state_dict = paddle.load("work/Gnet.pdparams")
Gopt_state_dict = paddle.load("work/Gadam.pdopt")
Gnet.set_state_dict(Glayer_state_dict)
optimizerG.set_state_dict(Gopt_state_dict)
In [93]
batch_size = 1noise = paddle.randn([batch_size,100,1,1],dtype = "float32") generated_image = Gnet(noise).numpy()import cv2 generated_image = np.transpose(generated_image, (0, 2, 3, 1)) generated_image = cv2.resize(generated_image[0], (32, 32), interpolation=cv2.INTER_LINEAR) plt.imshow(generated_image) plt.show()
 t;float32")
generated_image = Gnet(noise).numpy()import cv2
generated_image = np.transpose(generated_image, (0, 2, 3, 1))
generated_image = cv2.resize(generated_image[0], (32, 32), interpolation=cv2.INTER_LINEAR)
plt.imshow(generated_image)
plt.show()
t;float32")
generated_image = Gnet(noise).numpy()import cv2
generated_image = np.transpose(generated_image, (0, 2, 3, 1))
generated_image = cv2.resize(generated_image[0], (32, 32), interpolation=cv2.INTER_LINEAR)
plt.imshow(generated_image)
plt.show()<Figure size 640x480 with 1 Axes>
总结
- 我们这里只是使用相应灰度图片进行尝试,未对彩色通道尝试,彩色通道需要我们另作网络设计
- DCGAN的不足之处
- 对于复杂的数据集,DCGAN的表现可能不够好。虽然DCGAN使用了深度卷积神经网络,但是它仍然无法捕获一些复杂的数据集中的细节特征,例如物体之间的局部关系等。
- 在训练过程中,它可能容易出现训练不稳定的问题。DCGAN中的GAN模型训练是通过两个神经网络之间的博弈来实现的,这导致训练过程非常不稳定。在实践中,经常需要手动调整超参数和选择合适的损失函数才能使训练过程收敛。
- DCGAN生成的图像可能存在一定程度的模糊或失真。在生成大型高分辨率图像时,DCGAN难以保证图像细节的准确性和清晰度。这可能是由于GAN模型本身的生成机制不同于自然图像处理的方式。
- 生成的结果缺乏多样性。DCGAN在生成图像时缺乏多样性,即它往往只能生成与训练集类似的图像,而无法生成更多样化的图像。这使得生成的输出有时候会缺乏想象力和创造力。
以上就是手把手带你学会GAN的详细内容,更多请关注其它相关文章!
# ai
# python
# 自然语言
# 建邺seo优化首页
# 沧州高品质网站建设
# 浙江抖音营销推广商家
# 建设英文网站请示
# 网站建设定制改版方案
# 是由
# 这是
# 中文网
# 带你
# 一言
# 手把手
# 过程中
# 本网站
# 新力
# type
# fig
# seo产品介绍怎么快写
# 学校党支部网站建设
# 30岁能做seo吗
# 玉屏短视频营销推广
# 专门做营销推广的公司
相关栏目:
【
行业资讯67740 】
【
技术百科0 】
【
网络运营39195 】
相关推荐:
远程桌面如何发送命令
哪些明星在用苹果16
如何把一个命令后台运行
笔记本如何使用固态硬盘
光猫power灯一直闪是什么意思
typescript怎么拼接
typescript是什么软件
春运抢票多久可以买到票
阿里云盘共享账户怎么用
开机如何进入命令行模式
typescript怎么写call方法
如何自己加装固态硬盘
j*a怎么处理json数组
怎么下载360桌面壁纸
typescript数据怎么写
cmd如何定时执行命令
春运抢票软件哪个好
春运抢票要用抢票软件吗
什么是域名解析地址
跨境电商gmv是什么意思?跨境电商GMV:理解其含义、计算方法和影响因素
如何用dos命令启动u盘
安卓手机怎么打开5g
win10电脑如何使用命令提示符
苹果16promax有哪些颜色
划水是什么意思
ao3镜像网站永久地址入口
折叠屏手机共有哪些
阿里云盘扩容是什么_扩容阿里云盘方法是什么教程
春运返程如何抢票成功
windows 如何连接ftp命令行
kingston是什么_kingston是什么意思
linux如何查看命令的参数
单片机蓝牙怎么开启设备
广东春运几点抢票
typescript怎么加号
如何进入安卓命令行
苹果16有哪些不同
电动车eco和power是什么意思
为什么夸克下载不到
如何加装固态硬盘
如何安装大华固态硬盘
如何体验苹果16系统
折叠屏手机为什么这么小
尼桑越野车中控前power是什么意思
内网和外网区别 内网和外网有什么区别
typescript中如何定义json
对象数组怎么用j*a
新装固态硬盘如何安装
单片机怎么计算0xf0
typescript参数怎么用
